
The gaze-contingency paradigm is reshaping how researchers study visual attention. By linking eye movements to what appears on screen in real time, it turns perception into an interactive signal. Using techniques like foveal masking, peripheral magnification, and probe-based tasks, scientists can isolate attention with precision and test how biases form and change. Today, it’s often combined with eye tracking, EEG, and behavioral tools to reveal how we see, decide, and respond in dynamic environments.
Table of Contents
We pay attention to the things that matter in our lives – things that are important, or relevant to us. What those things are, and why they matter, can vary a lot between people. These differences in our attention will go a long way to defining our interests and personality, which can ultimately give an impression of our identity. Finding out what these differences are can help us answer some central questions of psychology – who we are, and why?
The gaze-contingency paradigm helps in answering that question, by isolating what we see, permitting psychologists to know exactly what the participant is looking at. This experimental setup is quite literally “what you see is what you get”. We know that people pay more attention to things that are salient (or unexpected) to them, and once we have precisely defined where that attention is focused, we can start to ask questions about why.
What exactly is a gaze-contingency task?
There are several answers to this question, as many different versions of this experimental setup exist. They all share one thing in common though – that of a dynamic and changing stimuli that responds to the participant’s gaze. The appearance of the stimuli is therefore gaze-contingent.
Let’s go through a few of the versions to get a clearer picture.
There are several modern variants of this task (that are discussed below), but some of the earliest gaze-contingency methodologies were constructed by Stephen Reder, in 1973. Within this, he described several paradigms (several of which were already existing in non-computerized forms), that centered around a stimuli being presented when the participant’s gaze was fixated upon a predefined location.
The reaction to the newly presented stimuli could then be measured, and compared to other types of presented stimuli (e.g. reaction time to pictures of different facial expressions), or to other participant’s responses.
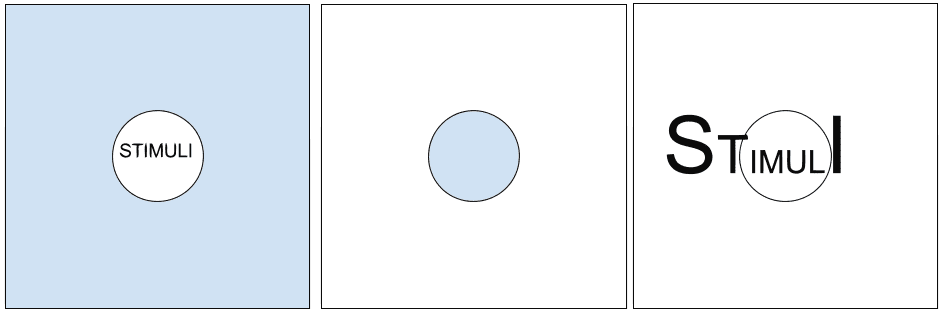
Firstly, Reder described an experimental setup “in which only a small region of the stimulus array being searched is displayed clearly during any fixation”. This is now known as the “moving window” paradigm, and is largely based on blocking the peripheral view so that any information outside that range is occluded (an example of this, and the other different blocking paradigms described by Reder are shown in the figure below). This scenario has been applied to both image-based, and text-based stimuli.
Secondly, and in a reversal of the above paradigm, blocking of the foveal view can occur, which leaves only the peripheral visual information (somewhat) visible. The participant’s vision is then much more restricted, allowing experimental tasks to explore how the outer part of vision reacts to a scene.
Thirdly, the peripheral information can also be magnified, to compensate for the decreased visual resolution that the parafoveal part of the eye is capable of (so that the visual information surrounding the focused area is visible as the result of its increase in size, relative to the distance from the fovea).
How is it used today?
The gaze-contingency paradigm is still widely in use, and as the technological difficulties with this experiment have decreased, the ease of setup and execution has also increased. There are fewer computational constraints, so a vast amount of possible gaze-contingent scenarios are now possible that may not have been previously.
While the paradigms described by Reder remain useful and are applied in research today, there have also been other additions to the repertoire of experimental setups using gaze-contingency.
An example of such a setup is the dot-probe task. Within this, participants are first shown a fixation point which is followed by two images (one on the left, one on the right), and then a “probe” that appears in the same location as one of the images (the “probe” is an image or shape that the participant is told to fixate upon when it appears).
If the location of the probe is congruent with the previously fixated-upon image, then the time to fixation will be short. Conversely, if the probe is shown at the location of the other image (that was not fixated upon), then the time to probe fixation will be longer. The speed of fixations is suggestive of a preference when the probe location is congruent, and suggestive of an aversion, when the probe location is incongruent.

If this setup is repeated across multiple trials, the experimenter can test all versions of this paradigm, and build up an idea of which image type is preferred.
This has been used in an attempt to change the attention bias of participants. Known as “attention bias modification”, the dot-probe task is implemented as above, but the probe may only appear after neutral stimuli, while the other image may show, for example, a distressing scene. The aim, therefore, is to non-consciously train the participant to attend to the neutral stimuli, and implicitly avoid the distressing stimuli, as their goal is to attend to the probe as quickly as possible. This can of course also be designed to work in the other direction, with training toward non-neutral stimuli.
In a similar experimental setup, it has been shown that participants diagnosed with major depressive disorder took a long time to disengage from emotionally charged stimuli. The participants were shown both a neutral, and emotional face, and were asked to attend to the neutral face. The disengagement duration from the emotional face is taken as evidence that the attentional bias can contribute to the continuation of the disorder.
Recent research has also shown preliminary success in using the gaze-contingency paradigm to train autistic schoolchildren in sustaining gaze and attention. Modifying visual response is only part of the use of gaze-contingency experiments, but may prove to be useful as a non-invasive and low-cost approach to behavioral change.
Other scenarios can now incorporate brain imaging (such as fMRI), or psychophysiological measurements, to complement the data that is produced, and give a deeper insight into the processes involved in such tasks.
How to set up a gaze-contingency paradigm
It’s clear that the gaze-contingency paradigm is both well established, and offers easily accessible insights for psychological research – so how can we set it up? By using iMotions, combined with a third-party platform (such as PsychoPy) through the iMotions API (application programming interface), the gaze-contingency setup can be easily implemented. This also means that a wide variety of different programs can be added and completed within iMotions, providing a huge amount of flexibility in experimental setup.
With the data from the eye tracking device being forwarded through the API, the returning data can shape the stimulus presentation in iMotions, which will also record the relevant metrics that are required to understand any attentional biases.
The results of such a paradigm can then be instantly shown, as displayed in the image below. Specific areas of interest (AOIs) can be selected, and information about those defined regions can be extracted. This allows a quick and intuitive way in which to view the data.

An example of such an experimental setup is shown below, running in iMotions with facial expression analysis running simultaneously.
In addition to eye tracking information, the combination of other biosensors with the gaze-contingency paradigm can provide more data, and is easily completed in iMotions. Using facial expression analysis to measure emotional valence can provide information about a participant’s feelings as they encounter the stimuli. This provides another layer to the information obtained from the experiment, going beyond routine metrics of attention, and informing conclusions about why the participant attended more (or less) to a particular stimuli.
The use of EEG and subsequent analysis of frontal asymmetry showing participant engagement levels can also further substantiate measurements of attentional bias. Utilizing recordings of physiological arousal, such as through GSR, or ECG, can help implicate the strength of the attentional engagement, particularly when paired with other psychophysiological recordings.
Conclusion
The gaze-contingency paradigm can be used in a variety of ways, and as a tool to reveal biases across a range of disorders or mental states. Requiring minimal explicit mental effort from participants ensures that this experimental setup can be widely used. By using iMotions, the experiment can be easily performed and expanded upon in numerous ways, adding both depth and accuracy to the data, and therefore, the conclusions of the study.
If you want to know more about how to use the gaze-contingency program in iMotions, or would like to learn about how iMotions can help your research, then feel free to contact us.
I hope you’ve enjoyed reading about the gaze-contingency task, the research that has been completed with it, and how you can use it yourself. If you’d like to learn more about how to perform great research, then check out our free pocket guide below!







