
Les données issues des biocapteurs alimentent la modélisation prédictive du comportement humain. En combinant plusieurs signaux – suivi oculaire, activité de la peau (EDA), électroencéphalogramme (EEG) et analyse faciale –, l’apprentissage automatique met en évidence des schémas liés à l’engagement, aux émotions et à la charge cognitive. En utilisant les biocapteurs comme référence, les chercheurs valident des modèles destinés à des applications concrètes, telles que l’efficacité publicitaire et la sécurité routière, permettant ainsi le développement d’une IA centrée sur l’humain qui traduit des processus physiologiques complexes en informations exploitables.
Table of Contents
Chez iMotions, nous sommes spécialisés dans les données : la collecte et l’analyse simplifiées des données issues de biocapteurs pour la recherche sur le comportement humain. L’un des sujets qui suscite régulièrement beaucoup d’intérêt est l’utilisation de ces données pour explorer la création de modèles prédictifs du comportement humain.
Les modèles prédictifs constituent le fondement de l’intelligence artificielle (IA). Souvent basés sur des méthodes d’apprentissage automatique (que nous expliquerons plus en détail ci-dessous), ils consistent à exploiter les tendances observées dans les données pour prédire l’évolution future de celles-ci. Cela permet à une machine de faire des prédictions sur le monde, c’est-à-dire de disposer d’une intelligence artificielle.
Ces modèles peuvent avoir des répercussions sur de nombreux secteurs, qu’il s’agisse de prédire le succès d’une campagne de marketing en ligne ou de créer des algorithmes émotionnels pour la prochaine génération de véhicules centrés sur l’humain. À une époque où « les données sont le nouveau pétrole », les informations issues des biocapteurs sont extrêmement prometteuses pour ceux qui savent les exploiter.
Cet article examine comment l’évolution d’une IA davantage centrée sur l’humain peut être stimulée par les données issues des biocapteurs. Mais pour y parvenir, nous devons d’abord comprendre ce qu’il advient de ces données.
Apprentissage automatique
Les data scientists utilisent de nombreux types d’algorithmes d’apprentissage automatique pour extraire des informations et des tendances à partir des données, mais, en général, ces algorithmes peuvent être classés en deux catégories : l’apprentissage supervisé et l’apprentissage non supervisé.
L’apprentissage supervisé peut être comparé à un « tuteur » (le data scientist) qui utilise un ensemble d’exemples corrects, ou données d’apprentissage, pour enseigner à un « élève » (l’algorithme) un ensemble particulier de relations.
Par exemple, le tuteur pourrait fournir des photos d’animaux, correctement identifiées, ainsi que certaines caractéristiques distinctives, comme la présence de taches, de rayures et/ou d’ailes. Une fois ces informations assimilées, si l’on présente à l’élève la photo d’un animal inconnu, il devrait être capable de deviner de quel animal il s’agit, en s’appuyant sur les informations sur lesquelles il a déjà été formé. Parmi les exemples d’algorithmes d’apprentissage supervisé, on peut citer les régressions et les machines à vecteurs de support.
L’apprentissage non supervisé, en revanche, ne repose pas sur cette relation tuteur-élève. Dans ce cas de figure, l’algorithme reçoit un ensemble de données sans réponses et doit identifier lui-même les schémas caractéristiques.
Dans cet exemple, l’élève reçoit donc un ensemble de photos d’animaux accompagnées de légendes et, sans aide, il identifie lui-même des similitudes ou des critères de classification auxquels nous n’aurions peut-être pas pensé auparavant : les taches et les rayures pourraient certainement convenir, mais les animaux pourraient aussi être classés par couleur, par nombre de pattes ou selon qu’ils vivent sur terre ou dans la mer (quel algorithme intelligent !). L’algorithme peut ensuite utiliser les règles qu’il a établies pour émettre des hypothèses lorsqu’on lui présente de nouvelles images. Parmi les exemples d’algorithmes d’apprentissage non supervisé, on peut citer le clustering k-means et l’analyse en composantes principales.
Apprentissage automatique
Exploration de données
Algorithme
Classification
Réseaux neuronaux
Apprentissage profond
IA
Autonome
Appliquer ces algorithmes à un domaine aussi complexe que le comportement humain et les émotions peut sembler une tâche intimidante. Cependant, les avantages sont évidents : l’apprentissage automatique permet de détecter et d’exploiter des schémas récurrents dans d’énormes ensembles de données comportant de multiples variables et dimensions – ce que notre cerveau a du mal à gérer.
Les biocapteurs sont particulièrement aptes à générer d’énormes volumes de données ; les tendances qui s’en dégagent sont très prometteuses pour aider à comprendre le comportement humain.
Mais comment les biocapteurs peuvent-ils concrètement contribuer à relever certains des défis liés à la recherche sur le comportement humain ? Nous allons examiner deux exemples ci-dessous.
Caractérisation du comportement humain
Les émotions et les comportements humains peuvent aller du plus simple au plus complexe. Si la description des facettes complexes du comportement humain n’est pas une mince affaire, les biocapteurs et l’apprentissage automatique peuvent s’avérer d’une aide précieuse. Prenons l’exemple de l’utilisation des biocapteurs dans la publicité :
Une question simple : est-ce que quelqu’un remarque la marque de mon entreprise dans une publicité ? Une solution possible : l’oculométrie.
Question d’un niveau de difficulté moyen : dans quelle mesure ma publicité captive-t-elle les téléspectateurs ? Solution envisageable : l’oculométrie, l’analyse des expressions faciales, l’activité électrodermique (EDA).
Question complexe : dans quelle mesure l’identité de marque et la fidélité à mon entreprise influencent-elles l’expérience du spectateur lorsqu’il regarde ma publicité ? Solutions possibles : suivi oculaire, analyse des expressions faciales, EDA, EEG, auto-évaluation, tests d’association implicite.
En règle générale, plus un comportement est complexe et abstrait, plus il faut disposer de biocapteurs (et de sources de données). Cependant, cela rend l’interprétation de ces données de plus en plus difficile. C’est là que l’apprentissage automatique peut intervenir.
La charge mentale constitue un excellent exemple de variable complexe ; il s’agit d’un concept essentiel dans la recherche sur les facteurs humains (pour en savoir plus sur la charge mentale et ses méthodes de mesure, cliquez ici). En résumé, il n’existe pas de définition opérationnelle unique de la charge mentale ; ce concept est multidimensionnel et nuancé, impliquant une interaction entre la nature objective d’une tâche et l’expérience subjective de la personne qui l’effectue.
De plus, les indicateurs utilisés pour définir la charge mentale varient souvent en fonction de la nature de la tâche et des mesures qui se sont révélées appropriées lors de recherches antérieures. Cela fait de la mesure de la charge cognitive un problème particulièrement épineux lorsqu’on utilise des biocapteurs. Cependant, c’est précisément pour ces raisons que la charge cognitive se prête particulièrement bien à l’utilisation d’algorithmes d’apprentissage automatique. Les algorithmes non supervisés, en particulier, sont les plus à même de repérer des modèles et des associations dans des ensembles de données apparemment disparates. Il est donc possible de créer votre propre définition opérationnelle de la charge de travail mentale, à partir des données que vous avez déjà collectées pour votre cas d’utilisation spécifique.
Données de référence
Il est difficile de mesurer le cerveau humain « dans la vie réelle ». Le comportement doit souvent servir d’indicateur des processus physiologiques. Heureusement, les données issues des biocapteurs sont couramment utilisées comme « données de référence ».
Les données de référence désignent les données qui reflètent la réalité des faits. Dans le cas des êtres humains, il peut s’agir de déterminer si une personne est réellement fatiguée, anxieuse ou distraite (etc.), plutôt que de se contenter de ce qu’elle dit, ce qui est susceptible d’être biaisé.
Cette approche convient particulièrement aux chercheurs qui souhaitent recourir à l’apprentissage automatique pour modéliser le comportement humain à l’aide de méthodes indirectes.
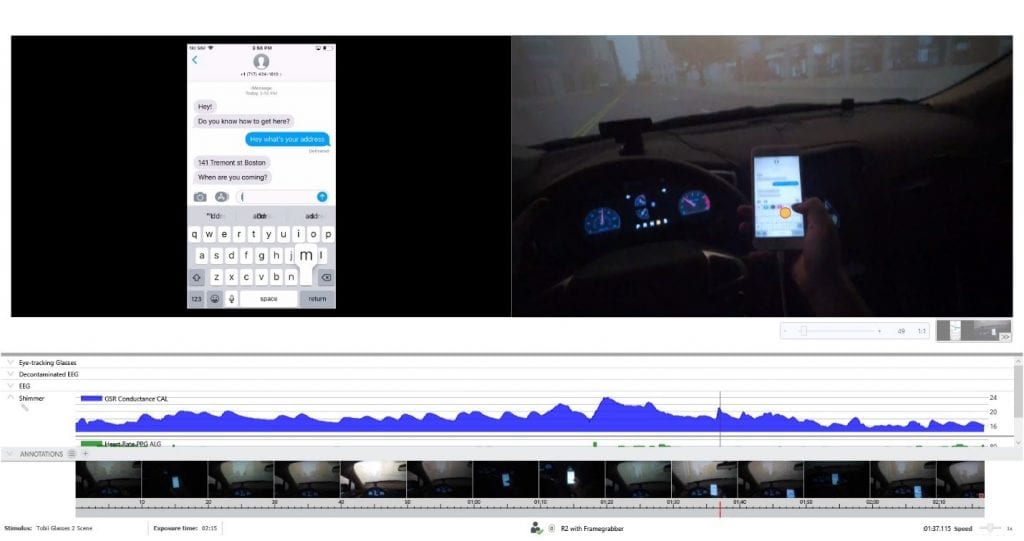
Cela se vérifie notamment dans le domaine de la mesure de la vigilance et de la somnolence dans l’industrie automobile. Si les équipementiers (OEM) s’intéressent aux nouvelles technologies permettant d’évaluer la vigilance et la somnolence du conducteur au volant, il est en effet très difficile d’installer un dispositif tel qu’un casque EEG dans l’habitacle d’une voiture.
Par ailleurs, plusieurs constructeurs ont tenté d’analyser la vigilance du conducteur à partir de données comportementales recueillies directement par le véhicule. Ces données peuvent notamment porter sur les conditions météorologiques, le temps passé au volant par le conducteur et la position du véhicule sur la voie.
Aucun de ces indicateurs ne constitue un signe direct de somnolence. Toutefois, comme ces données sont facilement accessibles et disponibles, il vaut la peine de les examiner comme indicateurs indirects de la somnolence au volant si cela peut contribuer à réduire le nombre d’accidents de la route.

Il est toujours recommandé de valider ce type de modèles comportementaux indirects par rapport à une « variable de référence » – par exemple, une mesure physiologique objective de la somnolence. De cette manière, nous pouvons nous assurer que le modèle reflète fidèlement l’état mental du conducteur et que ses évaluations de la somnolence sont précises.
Il existe de nombreux biocapteurs capables de caractériser la somnolence à partir de données de référence. L’activité électrodermique (EDA) et la fréquence cardiaque peuvent être utilisées pour refléter l’éveil physiologique, l’analyse des expressions faciales peut fournir des mesures de la fermeture des yeux, et l’électroencéphalographie peut servir à quantifier la prédominance des ondes thêta et delta dans le spectre de puissance d’un EEG, lesquelles sont associées à la somnolence et au sommeil. L’utilisation de biocapteurs pour valider les algorithmes renforce la confiance dans la précision du modèle et confère également une plus grande crédibilité scientifique. De plus, les biocapteurs peuvent aider à contextualiser et à réduire les erreurs de jugement et de prise de décision humaines, telles que les erreurs de type I et de type II. Découvrez également comment garantir que vos recherches sur le comportement humain produisent des résultats fiables en maîtrisant la gestion de la qualité des données.







