
Biosensordaten dienen als Grundlage für die prädiktive Modellierung menschlichen Verhaltens. Durch die Kombination verschiedener Signale – Eye-Tracking, EDA, EEG und Gesichtsanalyse – deckt maschinelles Lernen Muster in Bezug auf Aufmerksamkeit, Emotionen und kognitive Belastung auf. Unter Verwendung von Biosensoren als Referenzdaten validieren Forscher Modelle für praktische Anwendungen wie Werbewirksamkeit und Fahrersicherheit und ermöglichen so eine menschenzentrierte KI, die komplexe physiologische Vorgänge in umsetzbare Erkenntnisse umwandelt.
Table of Contents
Wir bei iMotions haben uns auf Daten spezialisiert – insbesondere auf die einfache Erfassung und Analyse von Biosensordaten für die Erforschung des menschlichen Verhaltens. Ein Thema, das regelmäßig auf großes Interesse stößt, ist die Nutzung von Biosensordaten zur Entwicklung von Vorhersagemodellen für menschliches Verhalten.
Vorhersagemodelle bilden das Fundament der künstlichen Intelligenz (KI). Sie basieren häufig auf Methoden des maschinellen Lernens (auf die wir weiter unten näher eingehen werden) und nutzen Muster in Daten, um Vorhersagen darüber zu treffen, wie zukünftige Daten aussehen werden. Dies ermöglicht es einer Maschine, Vorhersagen über die Welt zu treffen – also künstliche Intelligenz zu besitzen.
Diese Modelle können für viele Branchen von Bedeutung sein – von der Vorhersage des Erfolgs einer Online-Marketingkampagne bis hin zur Entwicklung emotionaler Algorithmen für die nächste Generation menschenzentrierter Fahrzeuge. In einer Zeit, in der „Daten das neue Öl“ sind, bergen die von Biosensoren gelieferten Informationen großes Potenzial für diejenigen, die wissen, wie man sie nutzt.
In diesem Artikel wird untersucht, wie die Entwicklung einer stärker auf den Menschen ausgerichteten KI durch Biosensordaten vorangetrieben werden kann. Doch um dies zu erreichen, müssen wir zunächst verstehen, was mit den Daten geschieht.
Maschinelles Lernen
Datenwissenschaftler nutzen viele verschiedene Arten von Algorithmen des maschinellen Lernens, um Erkenntnisse und Muster aus Daten zu gewinnen; im Allgemeinen lassen sich diese Algorithmen jedoch in zwei Kategorien einteilen: überwachtes und unüberwachtes Lernen.
Das überwachte Lernen lässt sich am besten mit einem „Lehrer“ (dem Datenwissenschaftler) vergleichen, der anhand einer Reihe korrekter Beispiele – der Trainingsdaten – einem „Schüler“ (dem Algorithmus) bestimmte Zusammenhänge beibringt.
Der Tutor könnte beispielsweise Fotos von Tieren bereitstellen, die korrekt beschriftet sind, sowie einige charakteristische Merkmale angeben, beispielsweise ob das Tier Flecken, Streifen und/oder Flügel hat. Nachdem der Schüler diese Informationen gelernt hat, sollte er in der Lage sein, anhand eines ihm unbekannten Tierfotos zu erraten, um welches Tier es sich handelt, und zwar auf der Grundlage der Informationen, die ihm zuvor vermittelt wurden. Zu den Algorithmen für überwachtes Lernen zählen beispielsweise Regressionsmodelle und Support-Vektor-Maschinen.
Beim unüberwachten Lernen hingegen gibt es diese Lehrer-Schüler-Beziehung nicht. In diesem Fall erhält der Algorithmus einen Datensatz ohne Antworten und muss selbstständig nach charakteristischen Mustern suchen.
In diesem Beispiel erhält der Schüler also eine Reihe von Tierfotos mit Beschriftungen, und ohne Hilfe findet er selbst Ähnlichkeiten oder Klassifizierungskriterien, an die wir zuvor vielleicht nicht gedacht hätten – Flecken und Streifen könnten sicherlich funktionieren, aber die Tiere könnten auch nach Farbe, der Anzahl der Beine oder danach klassifiziert werden, ob sie an Land oder im Wasser leben (was für ein cleverer Algorithmus!). Der Algorithmus kann dann die von ihm aufgestellten Regeln nutzen, um Vermutungen anzustellen, wenn ihm neue Bilder präsentiert werden. Beispiele für Algorithmen des unüberwachten Lernens sind unter anderem das k-Means-Clustering und die Hauptkomponentenanalyse.
Maschinelles Lernen
Data Mining
Algorithmus
Klassifizierung
Neuronale Netze
Deep Learning
KI
Autonom
Die Anwendung dieser Algorithmen auf etwas so Komplexes wie menschliches Verhalten und Emotionen mag wie eine gewaltige Aufgabe erscheinen. Die Vorteile liegen jedoch auf der Hand: Maschinelles Lernen ermöglicht es, Muster in riesigen Datensätzen zu erkennen und zu nutzen, die zahlreiche Variablen und Dimensionen umfassen – etwas, womit unser eigenes Gehirn nur begrenzt zurechtkommt.
Biosensoren sind besonders gut in der Lage, riesige Datensätze zu generieren – die darin enthaltenen Muster versprechen einen wichtigen Beitrag zum Verständnis des menschlichen Verhaltens.
Doch wie genau können Biosensoren dazu beitragen, einige der Herausforderungen in der Verhaltensforschung zu bewältigen? Im Folgenden werden wir zwei Beispiele näher betrachten.
Das menschliche Verhalten charakterisieren
Menschliche Emotionen und Verhaltensweisen können von einfach bis komplex reichen. Die Erfassung komplexer Facetten menschlichen Verhaltens ist zwar keine triviale Aufgabe, doch Biosensoren und maschinelles Lernen können dabei eine enorme Hilfe sein. Betrachten wir den Einsatz von Biosensoren in der Werbung:
Eine einfache Frage: Nimmt jemand die Marke meines Unternehmens in einem Werbespot wahr? Mögliche Lösung: Eye-Tracking.
Eine Frage mittlerer Schwierigkeit: Wie fesselnd wirkt mein Werbespot auf die Zuschauer? Mögliche Lösung: Eye-Tracking, Analyse der Mimik, elektrodermale Aktivität (EDA).
Komplexe Frage: Inwiefern beeinflussen die Markenidentität und die Markentreue meines Unternehmens das Erlebnis der Zuschauer beim Ansehen meines Werbespots? Mögliche Lösung: Eye-Tracking, Analyse der Mimik, EDA, EEG, Selbstauskunft, implizite Assoziationstests.
Generell gilt: Je komplexer und abstrakter das Verhalten, desto mehr Biosensoren (und desto mehr Datenquellen) sollten zur Verfügung stehen. Dies erschwert jedoch zunehmend die Interpretation dieser Daten. Hier kann maschinelles Lernen zum Einsatz kommen.
Ein gutes Beispiel für eine komplexe Variable ist die mentale Arbeitsbelastung, ein wichtiger Begriff in der Ergonomieforschung (mehr über mentale Arbeitsbelastung und deren Messung erfahren Sie hier). Zusammenfassend lässt sich sagen, dass es keine einheitliche operative Definition der mentalen Arbeitsbelastung gibt; der Begriff der Arbeitsbelastung ist vielschichtig und nuanciert und beinhaltet eine Wechselwirkung zwischen der objektiven Natur einer Aufgabe und der subjektiven Erfahrung der Person, die diese Aufgabe ausführt.
Zudem unterscheiden sich die zur Bestimmung der mentalen Arbeitsbelastung verwendeten Messgrößen oft je nach Art der Aufgabe und danach, welche Messgrößen sich in früheren Untersuchungen als geeignet erwiesen haben. Dies macht die Messung der kognitiven Arbeitsbelastung zu einem besonders kniffligen Problem bei der Verwendung von Biosensoren. Genau aus diesen Gründen eignet sich die kognitive Arbeitsbelastung jedoch hervorragend für den Einsatz von Algorithmen des maschinellen Lernens. Insbesondere unüberwachte Algorithmen haben die höchste Wahrscheinlichkeit, Muster und Zusammenhänge in scheinbar unzusammenhängenden Datensätzen zu erkennen. So ist es möglich, eine eigene operative Definition der mentalen Arbeitsbelastung zu erstellen, basierend auf den Daten, die Sie bereits für Ihren spezifischen Anwendungsfall gesammelt haben.
Referenzdaten
Das menschliche Gehirn lässt sich „im Alltag“ nur schwer messen. Oft muss das Verhalten als Indikator für physiologische Prozesse herangezogen werden. Glücklicherweise werden Biosensordaten häufig als „Referenzdaten“ verwendet.
Als „Ground-Truth-Daten“ werden Daten bezeichnet, die den tatsächlichen Sachverhalt widerspiegeln. Beim Menschen könnte dies beispielsweise bedeuten, ob jemand tatsächlich müde, ängstlich oder abgelenkt ist (und so weiter), anstatt sich nur auf das zu stützen, was er sagt – was leicht zu Verzerrungen führen kann.
Dies eignet sich besonders gut für Forscher, die maschinelles Lernen einsetzen möchten, um menschliches Verhalten mithilfe indirekter Methoden zu modellieren.
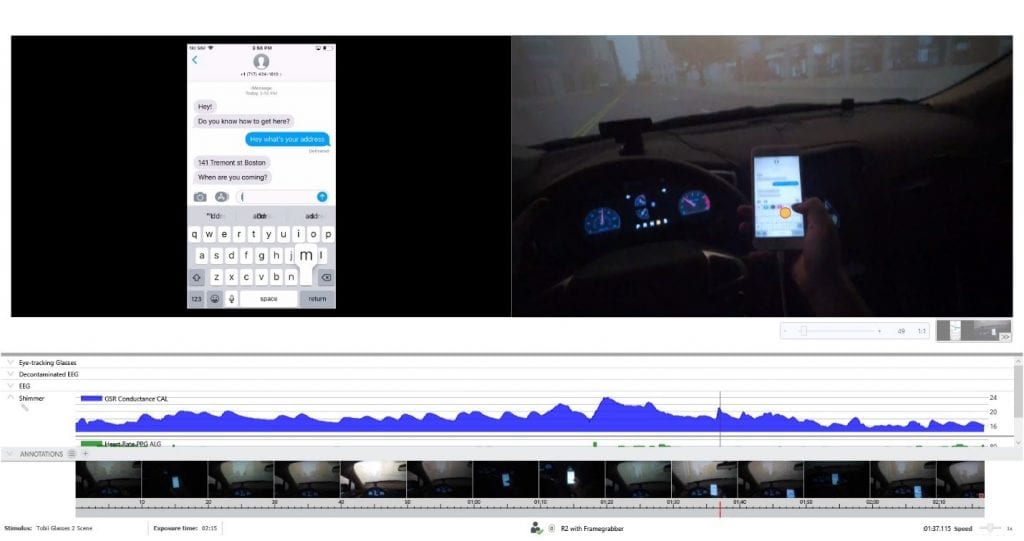
Dies zeigt sich an der Messung von Wachsamkeit und Schläfrigkeit in der Automobilindustrie. Während Erstausrüster (OEMs) an neuen Technologien zur Erfassung der Wachsamkeit und Schläfrigkeit des Fahrers während der Fahrt interessiert sind, ist es sehr schwierig, ein Gerät wie ein EEG-Headset im Fahrzeuginnenraum zu installieren.
Alternativ dazu haben mehrere Hersteller versucht, die Aufmerksamkeit des Fahrers anhand von Verhaltensdaten aus dem Fahrzeug selbst zu analysieren. Zu den Datenquellen könnten Wetterbedingungen, die Fahrzeit des Fahrers sowie die Position des Fahrzeugs auf der Fahrspur gehören.
Keine dieser Kennzahlen ist ein direkter Indikator für Müdigkeit. Da die Daten jedoch leicht zugänglich und ohne Weiteres verfügbar sind, lohnt es sich, sie als Indikatoren für die Müdigkeit von Fahrern zu untersuchen, wenn dies zu einer möglichen Verringerung der Zahl der Verkehrsunfälle führen könnte.

Es hat sich bewährt, solche indirekten Verhaltensmodelle anhand einer „Ground-Truth-Variablen“ zu validieren – beispielsweise anhand eines definitiven und physiologischen Maßes für Müdigkeit. Auf diese Weise können wir sicherstellen, dass das Modell den mentalen Zustand des Fahrers tatsächlich widerspiegelt und dass seine Einschätzungen der Müdigkeit zutreffend sind.
Es gibt zahlreiche Biosensoren, die Schläfrigkeit als Referenzdaten erfassen können. Die elektrodermale Aktivität (EDA) und die Herzfrequenz lassen sich zur Erfassung der physiologischen Erregung nutzen, die Gesichtsausdrucksanalyse liefert Messwerte zum Augenverschluss, und mittels Elektroenzephalografie lässt sich die Dominanz von Theta- und Deltawellen im EEG-Leistungsspektrum quantifizieren, die mit Schläfrigkeit und Schlaf in Verbindung stehen. Der Einsatz von Biosensoren zur Validierung von Algorithmen schafft mehr Vertrauen in die Genauigkeit des Modells und sorgt zudem für mehr wissenschaftliche Glaubwürdigkeit. Darüber hinaus können Biosensoren dabei helfen, menschliche Urteile und Entscheidungen in einen Kontext zu setzen und Fehler wie Typ-I- und Typ-II-Fehler zu reduzieren. Erfahren Sie außerdem, wie Sie durch die Beherrschung des Datenqualitätsmanagements sicherstellen können, dass Ihre Forschung zum menschlichen Verhalten zuverlässige Ergebnisse liefert.







