La modélisation par équations structurelles (SEM) est un outil précieux pour modéliser des concepts qui ne sont pas directement observables, tels que les attitudes ou les perceptions, à l’aide d’indicateurs mesurables. Cette approche est essentielle pour mieux comprendre les processus décisionnels humains, en particulier lorsqu’il s’agit d’intégrer des données provenant de sources diverses, telles que des enquêtes et des biocapteurs.
Table of Contents
La modélisation par équations structurelles (SEM) est une technique statistique qui permet aux chercheurs d’étudier les relations complexes entre des variables observées et des variables latentes. Dans le domaine de la psychoéconomie, par exemple, la SEM s’avère particulièrement utile, car elle intègre plusieurs concepts pour comprendre le comportement humain et les processus décisionnels influencés par des facteurs psychologiques et économiques. Contrairement aux méthodes de régression traditionnelles qui évaluent les relations directes entre les variables, la SEM permet d’analyser à la fois les effets directs et indirects, offrant ainsi une vision globale de l’interaction entre les différents facteurs.
En psychoéconomie, les chercheurs ont souvent affaire à des concepts qui ne sont pas directement observables, tels que les attitudes, les perceptions et les intentions. La modélisation structurelle des équations (SEM) permet de modéliser ces variables latentes en utilisant plusieurs indicateurs ou variables observables qui sont mesurables. Par exemple, pour étudier l’impact du stress financier sur la santé mentale, la SEM peut prendre en compte simultanément divers aspects tels que les revenus, les habitudes de consommation, les niveaux de stress et le bien-être psychologique, offrant ainsi une vision globale des interactions entre ces variables.
Un chapitre sur les variables : comment les utiliser dans la modélisation par équations structurelles
Comprendre les relations entre les cinq types de variables (variables indépendantes, variables dépendantes, variables de confusion, variables latentes et variables observées) est l’une des étapes essentielles à la construction de modèles précis et pertinents.
- Variables indépendantes (variables exogènes) :
- Il s'agit de variables qui ne sont pas influencées par d'autres variables du modèle. On peut les considérer comme des variables prédictives ou des causes.
- En SEM, les variables indépendantes peuvent influencer les variables dépendantes directement ou indirectement, par l'intermédiaire d'autres variables.
- Exemple : Prenons une étude qui examine l'impact du niveau d'éducation (variable indépendante) sur les performances professionnelles (variable dépendante). Dans ce cas, le niveau d'éducation est la variable prédictive qui influence les performances professionnelles.
- Variables dépendantes (variables endogènes) :
- Il s'agit de variables qui sont influencées par d'autres variables du modèle. On peut les considérer comme les résultats ou les effets.
- Dans l'analyse SEM, les variables dépendantes peuvent également jouer le rôle de médiateurs, en influençant d'autres variables dépendantes.
- Exemple : Dans cette même étude, la performance professionnelle est la variable dépendante influencée par le niveau d'éducation.
- Variables de confusion :
- Il s'agit de variables qui sont liées à la fois à la variable indépendante et à la variable dépendante et qui peuvent créer une association fallacieuse entre elles si elles ne sont pas correctement contrôlées.
- En SEM, il est nécessaire de tenir compte des variables de confusion afin d'éviter des estimations biaisées des relations entre les variables d'intérêt.
- Exemple : dans l'étude sur le niveau d'éducation et les performances professionnelles, la santé, tant mentale que physique, pourrait constituer une variable de confusion, car elle pourrait influencer à la fois le niveau d'éducation et les performances professionnelles.

- Variables latentes :
- Il s'agit de variables qui ne sont pas observées directement, mais qui sont déduites à partir d'autres variables observées (variables indicatrices).
- Les variables latentes représentent des concepts sous-jacents dont on suppose qu'ils sont à l'origine des variables observées. Elles constituent un concept central de l'analyse des modèles structurels (SEM) et sont généralement représentées par des cercles ou des ovales dans les diagrammes de chemins (voir le chapitre suivant).
- Parmi les variables latentes, on peut citer l'intelligence, la satisfaction générale, le statut socio-économique, la structure familiale, etc.
- Variables observées (variables manifestes) :
- Les variables observées, également appelées variables manifestes ou indicateurs, sont mesurées directement et fournissent les données utilisées pour déduire les variables latentes. Il s'agit des réponses ou des scores réels obtenus à partir d'enquêtes, de tests ou d'autres instruments de mesure (biocapteurs).
- En SEM, les variables observées servent à mesurer les variables latentes (en tant qu'indicateurs) et peuvent également faire office de variables indépendantes ou dépendantes.
Visualisation des modèles d’équations structurelles à l’aide de diagrammes de chemins
Dans cet exemple, nous avons choisi un diagramme de chemin très simple pour illustrer comment visualiser un SEM.
Pour reprendre l’exemple ci-dessus, nous allons nous concentrer sur l’impact du niveau d’éducation (variable indépendante) sur les performances professionnelles (variable dépendante). Nous pourrions donc choisir d’étudier uniquement l’influence du niveau d’éducation, en tant que variable prédictive, sur les performances professionnelles, en tant que variable de résultat.
Toutefois, pour obtenir une vision beaucoup plus globale, nous pouvons également choisir d’inclure un certain nombre de variables de précision. Ces variables peuvent être ajoutées afin de montrer que le niveau d’éducation et les performances professionnelles ne sont pas seulement des valeurs absolues en soi, mais qu’une multitude de facteurs entrent en jeu pour définir l’« éducation » ou les « performances professionnelles » d’une personne.
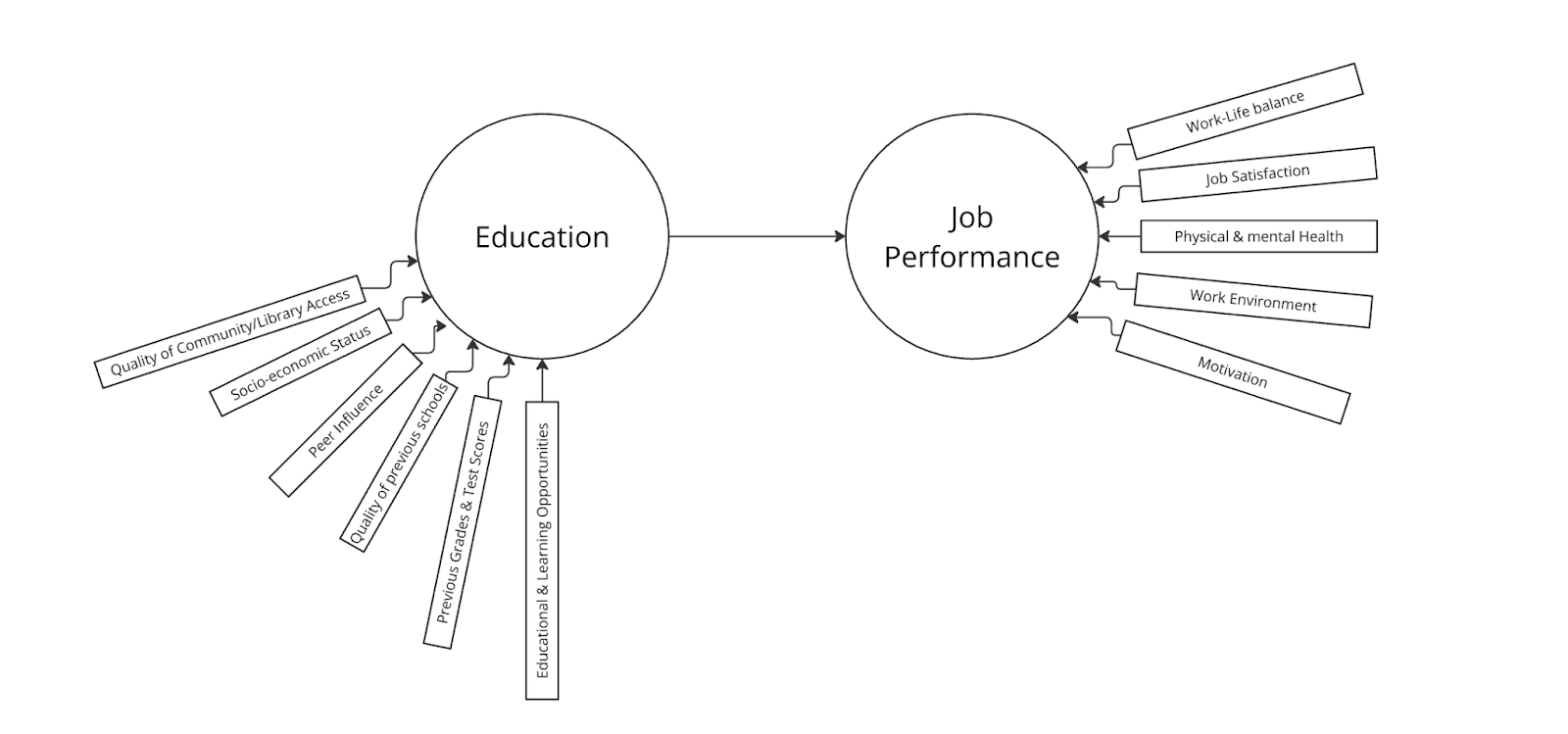
Le niveau d’éducation d’une personne peut être influencé par des facteurs tels que l’accès à une bibliothèque publique (et l’envie de l’utiliser), les possibilités d’apprentissage extrascolaires, des facteurs démographiques comme la qualité des écoles à proximité, ainsi que le statut socio-économique des parents. Les résultats scolaires antérieurs, généralement mesurés par les notes obtenues aux examens, peuvent également entrer en ligne de compte, tout comme des variables plus difficiles à quantifier, telles que l’influence des pairs, qui peuvent elles aussi avoir un impact sur le niveau d’éducation d’une personne.
Il pourrait s’agir de régressions individuelles permettant de prédire le niveau d’éducation global. De plus, il convient de reconnaître que les performances professionnelles ne dépendent pas uniquement du niveau d’éducation antérieur, mais aussi des conditions et des motivations qui influencent l’évaluation du poste lui-même ; il faudrait donc quantifier ces facteurs afin de déterminer dans quelle mesure la variance contribuant aux performances professionnelles est imputable à la seule éducation.
Une fois toutes ces variables intégrées au modèle simple « Formation -> Performance professionnelle », on pourrait obtenir quelque chose qui ressemblerait à ceci.
Pourquoi recourir à la modélisation par équations structurelles ?
Les modèles statistiques traditionnels se concentrent généralement sur l’analyse de l’effet direct d’une variable indépendante sur une variable dépendante. Cependant, ces modèles ne parviennent souvent pas à rendre compte des nombreux facteurs modérateurs et médiateurs susceptibles d’influencer cette relation. Pour isoler l’effet de la variable indépendante, les chercheurs doivent contrôler autant de variables de confusion que possible dans le cadre de la conception de l’étude, ce qui peut potentiellement réduire la validité écologique de celle-ci. Malgré cela, il est parfois crucial d’inclure toutes les variables dans un modèle complet et interconnecté, car elles agissent en tant que médiateurs et interagissent de manière complexe.
Vers un modèle d’équations structurelles
Exemple : les choix des milléniaux en matière de dons caritatifs
Pour illustrer la transition vers l’utilisation de la modélisation par équations structurelles (SEM), prenons l’exemple d’une étude portant sur les choix de dons caritatifs de la génération Y. Dans le cadre d’une étude contrôlée, les chercheurs pourraient restreindre leur champ d’analyse à un groupe démographique spécifique, tel que les personnes âgées de 35 à 40 ans, nées et ayant grandi à Copenhague, et disposant d’un revenu supérieur à 70 000 euros. Ils examineraient si et comment ces personnes s’engagent dans des activités caritatives.
Cette approche ciblée pourrait mettre en évidence une relation linéaire entre l’augmentation des revenus et le pourcentage des dépenses consacrées à des œuvres caritatives. Toutefois, en élargissant l’étude à une tranche d’âge plus large et à différents niveaux de revenus, les chercheurs peuvent examiner les effets d’interaction entre les différences générationnelles et les revenus sur les actions caritatives.

Lorsque les chercheurs prennent en compte d’autres facteurs implicites, tels que les opinions sociétales, ils doivent soit commencer à contrôler ces variables, soit élaborer des modèles de régression de plus en plus complexes. Par exemple, pour étudier les choix caritatifs d’une société cosmopolite et diversifiée comme celle de Copenhague, les chercheurs auraient besoin d’informations démographiques détaillées. Cela inclut l’âge, l’appartenance religieuse, les convictions politiques, l’utilisation des réseaux sociaux, les revenus personnels et familiaux, la situation familiale, l’âge des enfants le cas échéant, ainsi que le secteur d’activité.
Utilisation de biocapteurs pour améliorer les variables des équations structurelles
L’intégration des biocapteurs dans la modélisation par équations structurelles (SEM) renforce considérablement ses capacités en y ajoutant la dimension des variables observées. Les biocapteurs fournissent des données objectives en temps réel sur les réponses physiologiques telles que la variabilité de la fréquence cardiaque, la conductance cutanée et l’activité cérébrale. Ces mesures sont essentielles pour comprendre les processus biologiques sous-jacents qui accompagnent les comportements psychologiques et économiques dans les processus décisionnels. En intégrant les données des biocapteurs dans la SEM, les chercheurs peuvent créer des modèles plus précis et plus nuancés. Par exemple, ils peuvent étudier comment les réponses physiologiques au stress influencent la relation entre les difficultés économiques et la détresse psychologique.
Étapes pour la mise en œuvre de biocapteurs en microscopie électronique à balayage
Alignement des données issues des biocapteurs avec les modèles théoriques
Tout d’abord, les chercheurs doivent s’assurer que les données issues des biocapteurs correspondent aux concepts théoriques de leur modèle. Cela implique de valider les mesures physiologiques en tant qu’indicateurs des variables latentes étudiées. Par exemple, la variabilité de la fréquence cardiaque pourrait être validée comme indicateur de stress, tandis que la conductance cutanée pourrait l’être comme indicateur de l’excitation émotionnelle.
Intégration des données issues des biocapteurs aux données traditionnelles
Il convient ensuite d’intégrer les données recueillies par les biocapteurs aux données issues d’enquêtes ou d’observations traditionnelles. Cela nécessite des techniques sophistiquées de traitement des données pour synchroniser et analyser des flux de données multimodaux, un processus simplifié par l’utilisation d’iMotions, qui permet une synchronisation transparente et en temps réel des flux de données provenant de nombreuses sources.
Par exemple, les chercheurs pourraient recueillir des données d’enquête sur les niveaux de stress perçus et mesurer simultanément la variabilité de la fréquence cardiaque à l’aide d’un biocapteur. Le défi consiste à s’assurer que le moment et le contexte de ces mesures coïncident.

Utilisation de la modélisation par équations structurelles pour tester des hypothèses complexes
Une fois l’intégration des données terminée, la modélisation structurelle (SEM) peut être utilisée pour tester des hypothèses complexes concernant les relations entre des variables psychologiques, économiques et physiologiques. Par exemple, un chercheur pourrait recourir à la SEM pour vérifier si l’insécurité financière entraîne une augmentation du stress, qui à son tour provoque des modifications des réponses physiologiques contribuant à des problèmes de santé mentale. Un autre exemple pourrait être l’utilisation d’une tâche d’association implicite pour comprendre les préférences sociales et politiques, où les réponses physiologiques mesurées par des biocapteurs fournissent des informations plus approfondies.
Avantages de l’utilisation des données issues des biocapteurs en microscopie électronique à balayage
En combinant la SEM avec les données issues des biocapteurs, les chercheurs peuvent s’appuyer sur des mesures implicites et des réponses physiologiques plutôt que de se limiter aux données issues d’enquêtes basées sur les déclarations des participants. Cette approche présente plusieurs avantages :
- Mesure objective : les biocapteurs fournissent des données objectives en temps réel, qui ne sont pas faussées par des biais subjectifs ou des inexactitudes liées à l'auto-évaluation.
- Données enrichies : les données physiologiques, telles que le stress mesuré par ECG ou les préférences relevées par oculométrie, enrichissent le modèle SEM en y ajoutant des niveaux d'information difficilement capturables par les méthodes traditionnelles.
- Précision accrue : l'intégration des données issues des biocapteurs permet de développer des modèles plus fiables et plus précis, ce qui conduit à une meilleure compréhension des interactions complexes entre les variables.
Exemple d’application
Comme ce sujet peut s’avérer assez complexe, prenons un autre exemple. Imaginons une étude visant à explorer les effets de l’insécurité financière sur la santé mentale. Les méthodes traditionnelles pourraient s’appuyer sur des données autodéclarées concernant le stress financier et les résultats en matière de santé mentale. En intégrant des données issues de biocapteurs, les chercheurs peuvent ajouter des variables observées telles que la variabilité de la fréquence cardiaque et la conductance cutanée afin de mesurer les réponses physiologiques au stress. La SEM peut alors être utilisée pour vérifier si l’insécurité financière entraîne une augmentation du stress physiologique, qui à son tour a un impact sur la santé mentale. Cette approche holistique offre une compréhension plus complète des mécanismes par lesquels l’insécurité financière affecte le bien-être psychologique.