Im Laufe des letzten Jahrhunderts haben Forscher herausgefunden, dass der Klang unserer Stimme viel über uns selbst verraten kann, darunter auch über unsere Gefühlslage und mögliche Erkrankungen. Die Stimmenanalyse ist aufgrund ihrer Vielseitigkeit, ihrer nicht-invasiven Methode und ihrer geringen Zugangsbarrieren besonders leistungsstark. iMotions hat kürzlich eine neue Partnerschaft mit audEERING geschlossen, einem führenden Unternehmen in der Entwicklung von Stimmenanalysesoftware für Forschungszwecke.
Seit Jahresbeginn haben unsere Teams unermüdlich daran gearbeitet, ein neues Modul namens „Voice Analysis Module“ zu entwickeln, das es nun allen iMotions-Nutzern ermöglicht, ihre multimodalen Forschungsdesigns um eine Sprachanalyse zu ergänzen. Dieser Blogbeitrag ist der erste einer ganzen Reihe von Beiträgen, in denen wir näher darauf eingehen werden, wie die Sprachanalyse in der Forschung eingesetzt wird.
In diesem etwas längeren Blogbeitrag beschäftigen wir uns eingehend mit der Biologie unserer Stimme und damit, wie wir mithilfe von Forschungsinstrumenten wichtige Erkenntnisse für die Verhaltens- und Psychologieanalyse gewinnen können. Außerdem erörtern wir, wie die Stimmanalyse in der veröffentlichten Forschung eingesetzt wurde und was Sie bei der Durchführung von Forschungsarbeiten zur Stimmanalyse beachten müssen.
Die Biologie unserer Stimme und was wir daraus lernen können
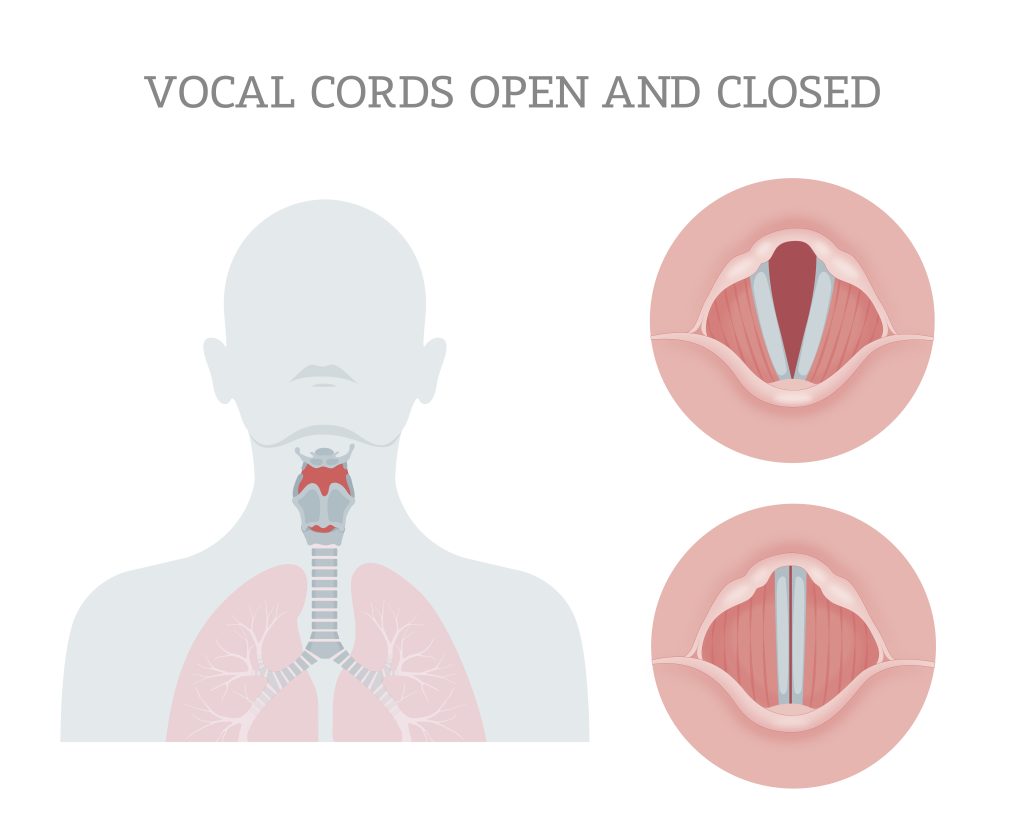
Unsere Stimme setzt sich aus einer Vielzahl von Schallwellen zusammen, die aus vielen verschiedenen Frequenzen bestehen. Die Schallwellen entstehen in unseren Stimmbändern, die durch zwei Muskeln, die sogenannten Stimmlippen, in Schwingung versetzt werden. Wenn Sie sprechen, schließen sich die Stimmlippen, während Luft aus Ihren Lungen durch sie strömt. Die durch die Stimmlippen strömende Luft versetzt diese in Schwingung und erzeugt so einen Ton.
Unsere Stimme setzt sich aus einer Vielzahl von Schallwellen zusammen, die aus vielen verschiedenen Frequenzen bestehen. Die Schallwellen entstehen in unserem Stimmapparat und werden vom Kehlkopf erzeugt, wo Muskeln die Spannung der beiden Stimmlippen – oft auch als Stimmbänder bezeichnet – steuern. Wenn Sie sprechen, schließen sich die Stimmlippen, während Luft aus Ihren Lungen durch sie strömt. Die durch die Stimmlippen strömende Luft versetzt diese in Schwingung und erzeugt so einen Ton.
Es gibt zwei gängige Methoden, die Laute unserer Stimmen zu klassifizieren:
- Obertöne: Obertöne sind die durch die Schwingung der Schallquelle (unserer Stimmlippen) erzeugten Schwingungen und werden durch die Form der Stimmlippen bestimmt.
- Formanten: Das sind die wichtigsten Resonanzfrequenzen, die durch die Größe und Form des Vokaltrakts entstehen. Sie erzeugen die typischen, unverwechselbaren Klänge von Sprachlauten wie /aah/ und /eeh/. Wenn du Stimm- oder Gesangsunterricht nimmst, trainierst du deinen Vokaltrakt direkt darauf, verschiedene Formanten zu erzeugen, die den ursprünglichen Klang verändern.
Obertöne und Formanten werden also durch unsere Biologie bestimmt, lassen sich aber auch durch Training verändern.
Aus Eigenschaften wie Obertönen und Formanten leiten wir die tatsächlichen Klangmerkmale ab, die wir bei der Stimmenanalyse untersuchen und interpretieren.
Diese Klangmerkmale lassen sich in drei Analyseebenen unterteilen. Sehen wir uns an, um welche es sich dabei handelt und wie sie mithilfe des Sprachanalysemodells von audEERING in iMotions gemessen werden.
Stufe 1: Prosodie – die grundlegendsten metrischen Merkmale, die sich aus der Stimmenanalyse ableiten lassen
Die prosodische Analyse ist der klassische Ansatz zur Analyse von Stimmen. Sie wird in der Regel für klinische und sprachwissenschaftliche Forschungszwecke eingesetzt. Die prosodische Analyse umfasst mehrere Merkmale. Hier konzentrieren wir uns auf die vier prosodischen Merkmale, auf die Sie in iMotions zugreifen können.
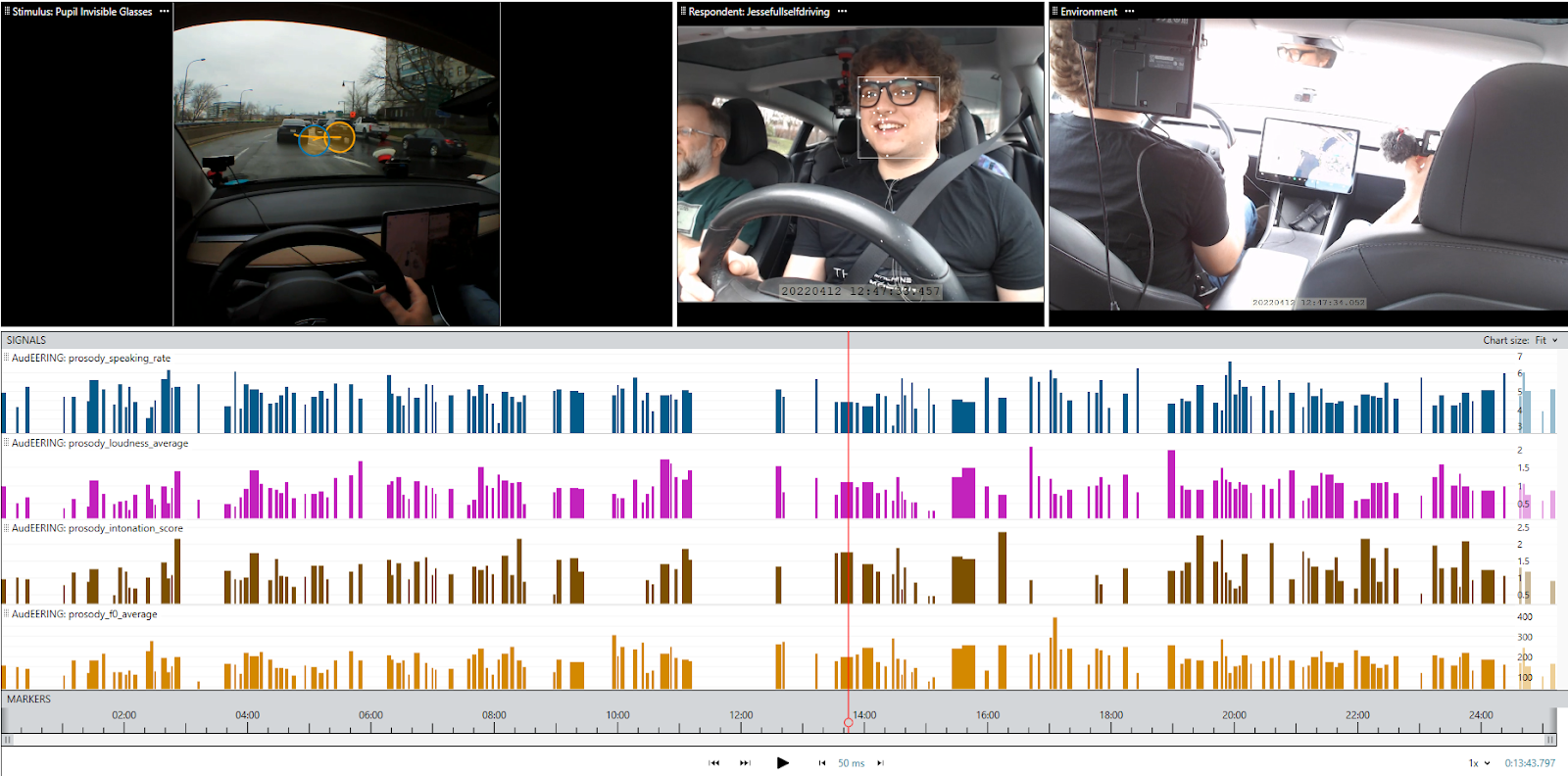
Bildunterschrift: Ein Beispiel für die Visualisierung von Sprachanalysedaten mit der Sprachanalyse in iMotions
- Tonhöhe: Die Tonhöhe bezieht sich auf die wahrgenommene Frequenz eines Tons, genauer gesagt darauf, wie hoch oder tief ein Ton wahrgenommen wird. Sie steht in engem Zusammenhang mit der Grundfrequenz einer Schallwelle, also der tatsächlichen physikalischen Frequenz, mit der die Schallwelle schwingt. Höhere Frequenzen führen zu einer höheren wahrgenommenen Tonhöhe, während niedrigere Frequenzen als tiefere Tonhöhe wahrgenommen werden.
Die Grundfrequenz wird als „F0“ bezeichnet und in Hertz (Hz) gemessen. Sie bezieht sich auf die Anzahl der Schwingungen der Stimmlippen oder Zyklen der Grundfrequenz, die in einer Sekunde auftreten. In iMotions erhalten Sie Zugriff auf vier statistische Kennzahlen zu F0, die über ein Sprachsegment berechnet werden: die minimale F0, die durchschnittliche F0, die maximale F0 und die Variation von F0. Welche Kennzahl am aussagekräftigsten ist, hängt von Ihrer Forschungsfrage ab.
Anhand der durchschnittlichen F0 lässt sich beispielsweise zwischen männlichen und weiblichen Stimmen unterscheiden (85–155 Hz bzw. 165–255 Hz). Eine hohe maximale F0 bei einer normalen durchschnittlichen F0 könnte auf spontane Stimmausbrüche mit hoher Tonhöhe hindeuten, wie etwa beim Ausdruck von Überraschung oder Ekel.
- Lautstärke: Die Lautstärke ist ein Maß dafür, wie laut ein Mensch ein Geräusch wahrnimmt. Sie hängt mit der Amplitude der Schallwelle zusammen, berücksichtigt jedoch auch die physiologischen Eigenschaften unseres Gehörs, die in der Fachwelt als Psychoakustik bezeichnet werden. Eine Schallwelle mit doppelter Amplitude wird von uns nicht als doppelt so laut wahrgenommen, sondern als etwa 1,4-mal lauter. Das Verhältnis zwischen der Amplitude einer Schallwelle und der wahrgenommenen Lautstärke ist nicht linear, sondern logarithmisch. Zudem ist unser Ohr empfindlicher für Frequenzen im mittleren Bereich (1–3 kHz), die wir als lauter wahrnehmen als tiefe oder hohe Frequenzen mit derselben Amplitude.
Die Lautheitsmessung in iMotions berücksichtigt diese Eigenschaften unseres Gehörs. Die Messung orientiert sich am wissenschaftlichen Lautheitsmodell von Zwicker, das die Lautheit in einer Einheit namens „Sone“ misst.
In iMotions wurde das Modell vereinfacht, um mit allen Arten von Schallquellen und Mikrofonen arbeiten zu können; daher erfolgt keine Kalibrierung auf physikalische Einheiten der Schallwellenenergie. Die Lautstärkemessung erfolgt als Skalenwert zwischen 0,0 (Stille) und 1,0 (maximal mögliche Lautstärke) ohne physikalische Maßeinheit.
Ähnlich wie bei F0 kann die Lautstärke eines Sprachsegments als Minimal-, Durchschnitts-, Maximal- oder Schwankungswert gemessen werden. Die Lautstärke wird in klinischen Studien regelmäßig angegeben, um zwischen verschiedenen Patientengruppen zu unterscheiden.
Aufgrund des Zusammenhangs zwischen Lautstärke und Signalamplitude wird die Lautstärkemessung durch den Aufnahmepegel des Mikrofons (Verstärkung) sowie durch den Abstand zwischen Mikrofon und Schallquelle (z. B. der sprechenden Person) beeinflusst. Wenn diese Bedingungen in Ihrem Setup variieren, sollten Sie Lautstärkewerte nicht unter diesen unterschiedlichen Bedingungen vergleichen, sondern unter konstanten Bedingungen, wie z. B. mit demselben Mikrofon (idealerweise Headset/Ansteckmikrofon in festem Abstand zum Mund) und denselben Aufnahmepegeln (deaktivieren Sie die automatische Aufnahmepegelsteuerung oder die automatische Verstärkungsregelung (AGC)!).
- Sprechgeschwindigkeit: Die Sprechgeschwindigkeit bezieht sich auf das Tempo, mit dem Sie sprechen, und wird als Anzahl der Silben pro Sekunde sowie deren Schwankung innerhalb eines Sprachsegments gemessen. Eine geringe Schwankung der Sprechgeschwindigkeit deutet auf ein gleichmäßiges Sprechtempo hin, während eine hohe Schwankung auf ein wechselndes Tempo hindeutet, z. B. eine Verlangsamung bei wichtigen Äußerungsteilen und eine Beschleunigung bei weniger wichtigen Teilen. Eine hohe Schwankung könnte auch auf gefüllte Pausen und Zögerungen (wie „äh“) hinweisen, die durch lautes Nachdenken oder eine höhere kognitive Belastung bedingt sind. Werte der durchschnittlichen Sprechgeschwindigkeit von 3–5 gelten als normal, unter 3 als langsamere Sprache und über 5 als schnellere Sprache. Wenn es in einem Sprachsegment mehr Pausen gibt, kann der gemessene Durchschnittswert niedriger sein als die tatsächlich wahrgenommene Sprechgeschwindigkeit.
- Intonation: Die Intonation ist ein Maß für die Höhen- und Tiefenbewegungen der Stimme (d. h. ein Maß dafür, wie stark die Tonhöhe innerhalb eines Sprachsegments variiert). Sie eignet sich dazu, zu messen, wie monoton (niedriger Intonationswert) oder lebhaft (hoher Intonationswert) eine Person spricht. Die Satzstruktur wird nicht berücksichtigt, d. h. es wird keine umfassende Analyse der Intonationsmuster durchgeführt. Intonationswerte werden aus der Standardabweichung der Tonhöhe abgeleitet und liegen typischerweise im Bereich von 0,4 bis 1,6.
Werte unter 0,4 weisen auf monotone Sprache
hin. Werte über 1,6 weisen auf lebhaftes Sprechen
hin. Werte von 1,0 weisen auf eine normale, durchschnittliche Intonation hin.
Stufe 2: Emotionale Dimensionen – das Einfangen emotionaler Ausdrucksformen in der Stimme
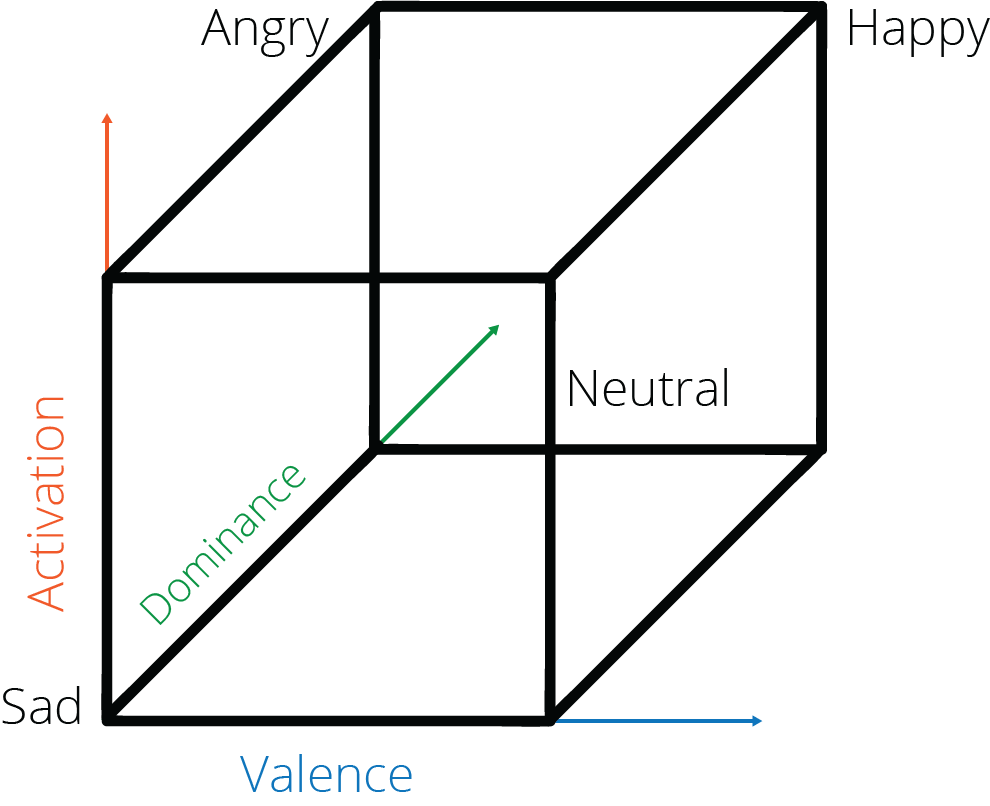
Die Analyse emotionaler Dimensionen ist besonders nützlich in der Sozial- und Verhaltensforschung, die sich mit Persönlichkeitsmerkmalen und Leistungsfähigkeit befasst. Es gibt drei emotionale Dimensionen, die üblicherweise in einem dreidimensionalen Raum mit bipolaren Achsen dargestellt werden (siehe Abbildung auf Seite X) (Abbildungsverweis)). Alle diese Messgrößen für emotionale Dimensionen werden als Werte im Bereich von -1 bis +1 angegeben.
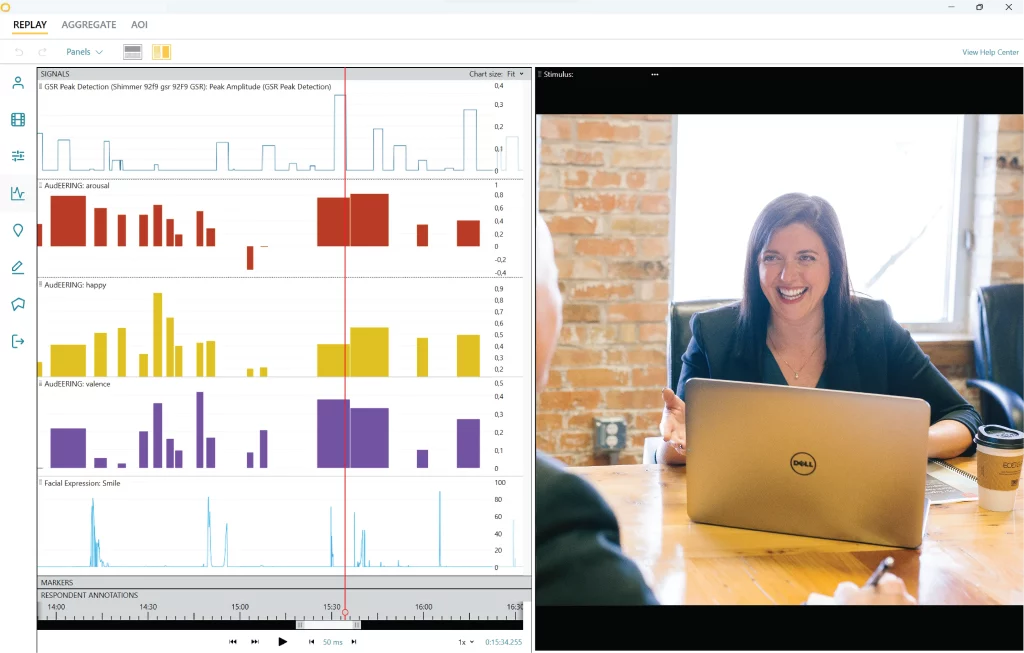
Bildunterschrift: Ein Beispiel für die Visualisierung von Sprachanalysedaten mit der Sprachanalyse in iMotions
- Erregung: Die Erregung gibt den Erregungsgrad einer Stimme an und wird auf einer Skala von hoch bis niedrig gemessen. Anhand der Erregung lässt sich ableiten, ob ein Ereignis eine beruhigende/entspannende oder aufregende/aufwühlende Wirkung auf eine Person hatte.
Im Allgemeinen können niedrige Erregungswerte (näher an -1) als Hinweis auf Traurigkeit, Entspannung, Müdigkeit, Depression oder Zufriedenheit interpretiert werden. Hohe Erregungswerte (näher an +1) deuten hingegen typischerweise auf Freude, Angst, Empörung oder Aufregung hin. - Dominanz: Dominanz gibt den Dominanzgrad der Stimme an und wird auf einer Skala von niedrig bis hoch gemessen. Anhand der Dominanz lässt sich ableiten, wie unterwürfig oder dominant sich ein Sprecher fühlt.
In der Regel deutet eine niedrige Dominanz auf einen Zustand der Angst hin, während eine hohe Dominanz einen Zustand des Stolzes anzeigt. - Valenz: Die Valenz gibt die emotionale Färbung einer Stimme an und wird auf einer Skala von positiv bis negativ gemessen. Anhand der Valenz lässt sich ableiten, ob ein Ereignis eine unangenehme/negative oder angenehme/positive Wirkung auf eine Person hatte.
Im Allgemeinen deutet eine negative Valenz auf einen Zustand von Wut, Traurigkeit, Angst, Kummer oder Langeweile hin. Im Gegensatz dazu deutet eine positive Valenz auf einen Zustand der Entspannung, Zufriedenheit, Freude und Begeisterung hin.
Stufe 3: Emotionserkennung
Die höchste Datenebene, die emotionale Zustände auf der Grundlage der Prosodie und emotionaler Dimensionen ableitet.
Diese Kennzahl ist besonders nützlich für Studien, in denen die Leistung und die emotionale Reaktion von Menschen auf Ereignisse untersucht werden.
Im Bereich der Stimmenanalyse gibt es vier Emotionskategorien, die aus der Stimme abgeleitet werden und auf die Sie in iMotions – basierend auf der Stimmenanalysesoftware von AudEERING – zugreifen können. Diese sind: fröhlich, neutral, traurig und wütend. Ihre Werte reichen von 0 bis 1, wobei jedes Stimmsegment einen Emotionswert von 1 ergibt. Die Emotion mit dem höchsten Wert (d. h. näher an 1) stellt die dominierende Emotion während dieses Stimmsegments dar.
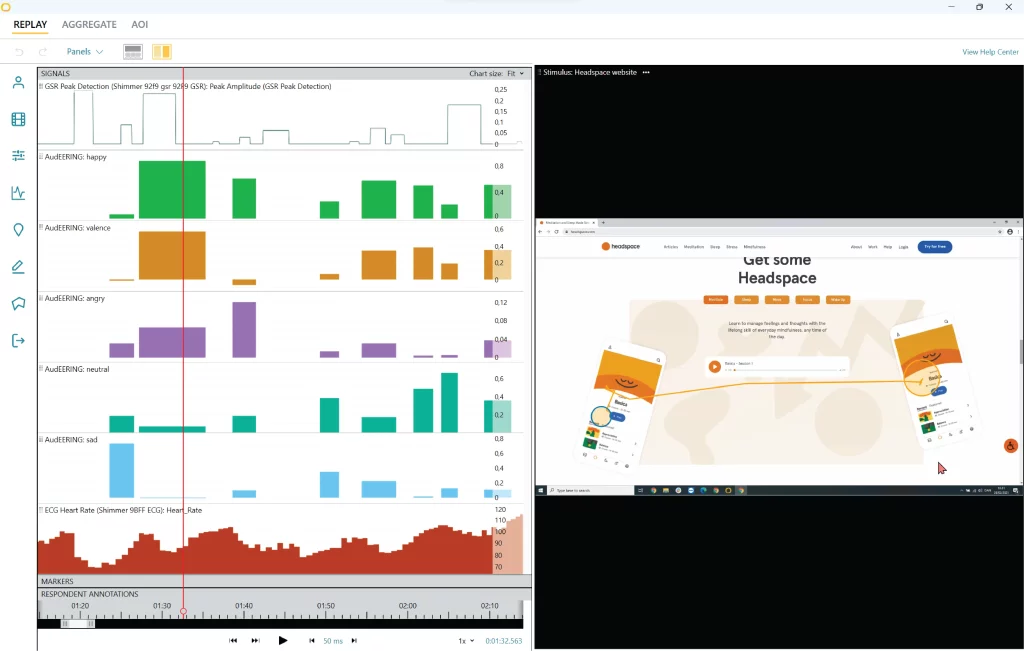
Bildunterschrift: Ein Beispiel für die Visualisierung von Sprachanalysedaten mit der Sprachanalyse in iMotions
Emotionsdimensionen und Emotionskategorien werden häufig in einem dreidimensionalen Raum mit bipolaren Achsen dargestellt, wodurch veranschaulicht wird, wie die Werte der Emotionsdimensionen mit den Emotionswerten korrelieren (siehe Abbildung).
Wie nutzen Forscher die Stimmungsanalyse?
Die Stimmungsanalyse findet in allen Anwendungsbereichen Verwendung, doch ihr Nutzen zeigt sich besonders deutlich im Kontext der klinischen Forschung. So lassen sich beispielsweise mithilfe der Stimmungsanalyse Biomarker für die Parkinson-Krankheit, Depressionen und bösartige Kehlkopfpolypen identifizieren. Auch in den Sozial- und Verhaltenswissenschaften wird die Stimmungsanalyse zunehmend eingesetzt, um Veränderungen im emotionalen Befinden zu erkennen. Wir bei iMotions freuen uns, dass die Stimmenanalyse in neue Forschungsfelder wie Automobiltechnik, Human Factors und Leistungswissenschaft vordringt. Im Folgenden stellen wir zunächst Beispiele dafür vor, wie die Stimmenanalyse in drei verschiedenen Forschungsbereichen angewendet wird, und zeigen anschließend, wie sie in unterschiedlichen Forschungsdesigns zum Einsatz kommt.
Es gibt drei Hauptforschungsbereiche, in denen die Sprachanalyse zum Einsatz kommt:
- Klinische Forschung: In der klinischen Forschung wird die Stimmenanalyse seit Jahrzehnten eingesetzt, um zwischen verschiedenen Patientengruppen zu unterscheiden. So wurden beispielsweise in Studien Stimmbiomarker für dysarthrische Sprache, Depression, Alzheimer und Parkinson identifiziert (Narendra und Alkul, 2018; Bocklet et al., 2013; Taguchi et al., 2018; Han et al., 2018; Meilan et al., 2013). In der klinischen Forschung wird die Stimmenanalyse auch zur Beurteilung der Wirksamkeit von Behandlungen eingesetzt. So wurde beispielsweise in einer Studie die Wirksamkeit einer Behandlung von sozialer Angst mithilfe der Stimmenanalyse bewertet (Laukka et al., 2008).
In der klinischen Forschung wird die Stimmenanalyse typischerweise im Rahmen streng kontrollierter Laborstudien veröffentlicht, bei denen die Teilnehmenden eine Sprechaufgabe vor einem Computer ausführen, oder als Teil eines klinischen Interviews.
- Sozial- und Verhaltensforschung: Die Stimmenanalyse ist in den Sozial- und Verhaltenswissenschaften sehr beliebt, um besser zu verstehen, wie unsere Stimme unsere Persönlichkeit widerspiegelt, wie sie sich auf unsere Mitmenschen auswirkt oder wie verschiedene Faktoren unsere Wahrnehmung anderer Stimmen beeinflussen. So haben beispielsweise bekannte Studien untersucht, wie sich der Menstruationszyklus auf die Präferenz von Frauen für bestimmte Merkmale männlicher Stimmen auswirkt (Puts, 2005), während andere Studien untersuchten, wie sich eine Veränderung des Klangs der eigenen Stimme auf die Selbstwahrnehmung auswirkt (Stel et al., 2011). Die Stimmenanalyse wurde auch zur Vorhersage von Wahlergebnissen eingesetzt (Banai et al., 2017).
Genau wie in der klinischen Forschung führen Sozial- und Verhaltenswissenschaften ihre Untersuchungen zur Stimmenanalyse oft in kontrollierten Laborumgebungen durch. In diesem Forschungsbereich ist es jedoch üblicher, vorab aufgezeichnete Video- oder Audiodateien zu verwenden, um Stimmen aus der „realen Welt“ zu analysieren.
- Marketing- und Wirtschaftsforschung: In der Marketing- und Wirtschaftsforschung wird die Stimmungsanalyse eingesetzt, um verschiedene Aspekte ihrer Kernaufgaben zu optimieren, darunter Kommunikations- und Vertriebsstrategien. Wirtschaftsforscher veröffentlichen ihre Ergebnisse meist nicht, doch ist allgemein bekannt, dass die Stimmungsanalyse kommerziell in Callcentern und im UX-Design genutzt wird.
- Die Sprachanalyse ist aufgrund ihrer Vielseitigkeit bei der Datenerhebung besonders leistungsstark. Daher wird sie häufig in sehr unterschiedlichen Studiendesigns eingesetzt. Zu den gängigsten Studiendesigns, bei denen die Sprachanalyse zum Einsatz kommt, gehören die folgenden:
- Think-aloud-Tests: Bei Think-aloud-Tests handelt es sich um ein Untersuchungsdesign, bei dem die Teilnehmer angewiesen werden, ihre Gedanken laut auszusprechen, während sie eine Aufgabe ausführen. Diese Strategie wird häufig in der User-Experience-Forschung eingesetzt, siehe zum Beispiel diese Studien: https://dl.acm.org/doi/abs/10.1145/3325281 + https://www.mingmingfan.com/papers/CHI21_OlderAdults_ThinkAloud_UXProblems.pdf
- Dyadische Interaktionen: Der Begriff „Dyade“ bezieht sich auf zwei Personen, die miteinander kommunizieren. Die Dyadenforschung unterscheidet sich von Interviews zwischen einem Interviewer und einem Befragten (siehe unten), da sie in der Regel in Form von natürlichen Gesprächen zwischen zwei Kollegen, Freunden oder Diskussionsteilnehmern stattfindet. Beispielsweise kann die Stimmenanalyse eingesetzt werden, um den emotionalen Zustand von Dyaden während einer Teamaufgabe zu bewerten (https://dl.acm.org/doi/abs/10.1145/3136755.3136804) oder um den Tonfall (und dessen Modulation) zwischen Personen mit niedrigem und hohem Status zu untersuchen (https://psycnet.apa.org/doiLanding?doi=10.1037%2F0022-3514.70.6.1231).
- Präsentationen: Eine mitreißende Stimme bei Präsentationen wird immer wichtiger, und die Stimmenanalyse hat bereits dazu beigetragen, zwischen sehr mitreißenden und wenig mitreißenden Rednern zu unterscheiden. Siehe zum Beispiel diese Studie, in der die Stimmmerkmale von Steve Jobs während Präsentationen mit denen eines durchschnittlichen Redners verglichen werden:
https://www.sciencedirect.com/science/article/abs/pii/S0747563216304873 . In diesem Sinne ist es sinnvoll, die Stimmungsanalyse zur Leistungsoptimierung und im Coaching für öffentliche Reden einzusetzen. - Gespräche: Gespräche sind ein fester Bestandteil des Arbeitsalltags und im Gesundheitswesen. Klinische Gespräche wurden im Hinblick auf die Stimmenanalyse besonders intensiv untersucht, beispielsweise bei Depressionen (https://dl.acm.org/doi/abs/10.1145/2663204.2663238), bei koronaren Herzerkrankungen (https://journals.lww.com/psychosomaticmedicine/Citation/1977/07000/Assessment_of_Behavioral_Risk_for_Coronary_Disease.3.aspx.)
- Automobilbranche: Auch wenn es sich hierbei noch um ein neues Gebiet handelt, ist die Stimmenanalyse für die Automobilforschung vielversprechend. Ein wesentlicher Grund für dieses Potenzial liegt darin, dass die Stimmenanalyse ein nicht-invasiver Sensor ist, der im Fahrzeug aufgezeichnet werden kann, ohne dass die Person zusätzliche Hardware tragen muss (allerdings sollte man je nach Umgebungsgeräuschen ein Mikrofon in Betracht ziehen, um die bestmögliche Qualität zu erzielen). Die Sprachanalyse wurde bereits zur Erkennung von Müdigkeit und Substanzkonsum eingesetzt und könnte für Automobilunternehmen, die bestrebt sind, den kognitiven Zustand eines Fahrers automatisch zu ermitteln, eine bahnbrechende Neuerung darstellen. Wir haben interne Studien durchgeführt, um die Machbarkeit dieses Ansatzes zu demonstrieren.
- Think-aloud-Tests: Bei Think-aloud-Tests handelt es sich um ein Untersuchungsdesign, bei dem die Teilnehmer angewiesen werden, ihre Gedanken laut auszusprechen, während sie eine Aufgabe ausführen. Diese Strategie wird häufig in der User-Experience-Forschung eingesetzt, siehe zum Beispiel diese Studien: https://dl.acm.org/doi/abs/10.1145/3325281 + https://www.mingmingfan.com/papers/CHI21_OlderAdults_ThinkAloud_UXProblems.pdf
Was ist bei der Durchführung von Sprachanalysen zu beachten?
Wie bei jeder anderen Art von Forschung gibt es auch hier einige Dinge zu beachten, wenn Sie Ihre Experimente konzipieren und Daten von höchster Qualität erheben.
Zunächst sollten Sie sicherstellen, dass Sie ein geeignetes Mikrofon verwenden und die Aufnahme in einer geeigneten Umgebung durchführen. Was das Mikrofon betrifft, so verfügen die meisten Computer, die ab 2020 hergestellt wurden, über integrierte Mikrofone, die sich hervorragend für die Aufnahme von Sprachaufzeichnungen zur Analyse eignen. Je nach Ihrer Konfiguration sollten Sie jedoch die Verwendung eines externen Mikrofons in Betracht ziehen. Verwenden Sie in diesem Fall unbedingt ein über USB angeschlossenes Mikrofon einer renommierten Marke. Was die Aufnahmeumgebung betrifft, ist es immer ratsam, Daten an einem Ort ohne starken Lärm aufzunehmen. Dies kann im Labor, in einem Büro oder bei den Teilnehmenden zu Hause sein (denken Sie jedoch daran, sie zu bitten, den Fernseher auszuschalten und den Hund im Garten zu lassen!).
Es wird empfohlen, für jeden Reiz von jedem Teilnehmer mindestens 60 Sekunden Sprachdaten zu erfassen. Wenn Sie vorhaben, Ihre Daten gruppenübergreifend zusammenzufassen, sollten Sie mit einer Stichprobengröße von 20 bis 40 Personen (pro Gruppe) rechnen. Diese Empfehlung hängt natürlich vom Zweck der Studie und den präsentierten Reizen ab.
Wie Sie herausfinden, ob eine Stimmenanalyse das Richtige für Sie ist
Mittlerweile wissen Sie, wie wir Stimmmerkmale messen und nutzen können, um mehr über menschliches Verhalten, Kognition und Leistungsfähigkeit zu erfahren, und Sie wissen, wie andere Forscher diese Technologie einsetzen. Vielleicht fragen Sie sich, ob auch Ihre eigene Forschung von einer Stimmenanalyse profitieren könnte. Im Folgenden finden Sie einige Leitfragen, die Sie sich stellen können:
- Beziehen sich Ihre Experimente auf Teilnehmer, die entweder ganz natürlich sprechen (z. B. in Gesprächen oder als Reaktion auf ein Erlebnis) oder im Rahmen des Studiendesigns (z. B. in einem Interview oder einem Think-Aloud-Test)?
- Möchtest du mehr über die Gefühlslagen anderer Menschen erfahren?
- Sind Sie daran interessiert, neue Biomarker zu identifizieren oder Vorhersagemodelle für verschiedene Diagnosen zu erstellen?
Wenn Sie eine dieser Fragen mit „Ja“ beantworten können, könnte die Stimmenanalyse genau das Richtige für Sie sein!
Aber Moment mal: Die Stimmenanalyse ist zwar eine spannende Ergänzung für Ihre Forschung, doch sie ist nur eine von vielen Technologien, mit denen sich das Verhalten, die Gedanken und die Emotionen von Menschen untersuchen lassen. Die Stimmenanalyse erfasst einzigartige Aspekte des menschlichen Verhaltens, die andere Sensoren nicht erfassen können, doch ihre Aussagekraft ist in Kombination mit anderen Sensoren – wie der Analyse des Gesichtsausdrucks, der Blickverfolgung und der elektrodermalen Aktivität – deutlich größer.