Die Strukturgleichungsmodellierung (SEM) eignet sich hervorragend dazu, nicht direkt beobachtbare Konstrukte wie Einstellungen oder Wahrnehmungen mithilfe messbarer Indikatoren zu modellieren. Dieser Ansatz ist entscheidend, um tiefere Einblicke in menschliche Entscheidungsprozesse zu gewinnen, insbesondere bei der Zusammenführung von Daten aus unterschiedlichen Quellen wie Umfragen und Biosensoren.
Table of Contents
Die Strukturgleichungsmodellierung (SEM) ist eine statistische Methode, mit der Forscher komplexe Zusammenhänge zwischen beobachteten und latenten Variablen untersuchen können. Im Kontext der Psychoökonomie beispielsweise ist SEM besonders wertvoll, da sie mehrere Konstrukte integriert, um menschliches Verhalten und Entscheidungsprozesse zu verstehen, die von psychologischen und wirtschaftlichen Faktoren beeinflusst werden. Im Gegensatz zu herkömmlichen Regressionsmethoden, die direkte Beziehungen zwischen Variablen untersuchen, kann SEM sowohl direkte als auch indirekte Effekte bewerten und liefert so ein umfassendes Bild davon, wie verschiedene Faktoren zusammenwirken.
In der Psychoökonomie beschäftigen sich Forscher häufig mit Konstrukten, die nicht direkt beobachtbar sind, wie beispielsweise Einstellungen, Wahrnehmungen und Absichten. Die Strukturgleichungsmodellierung (SEM) hilft dabei, diese latenten Variablen zu modellieren, indem sie mehrere Indikatoren oder beobachtbare Variablen nutzt, die messbar sind. Um beispielsweise die Auswirkungen finanzieller Belastungen auf die psychische Gesundheit zu untersuchen, kann die SEM verschiedene Aspekte wie Einkommen, Ausgabeverhalten, Stresslevel und psychisches Wohlbefinden gleichzeitig berücksichtigen und so einen ganzheitlichen Überblick über die Wechselwirkungen zwischen diesen Variablen bieten.
Ein Kapitel über Variablen – Wie man sie in der Strukturgleichungsmodellierung verwendet
Das Verständnis der Zusammenhänge zwischen den fünf verschiedenen Variablentypen (unabhängige Variablen, abhängige Variablen, Störvariablen, latente Variablen und beobachtete Variablen) ist einer der wichtigsten Schritte zur Erstellung präziser und aussagekräftiger Modelle.
- Unabhängige Variablen (exogene Variablen):
- Dies sind Variablen, die nicht von anderen Variablen im Modell beeinflusst werden. Man kann sie als Prädiktoren oder Ursachen betrachten.
- In der SEM können unabhängige Variablen abhängige Variablen direkt oder indirekt über andere Variablen beeinflussen.
- Beispiel: Nehmen wir eine Studie, in der der Einfluss von Bildung (unabhängige Variable) auf die Arbeitsleistung (abhängige Variable) untersucht wird. In diesem Fall ist Bildung der Prädiktor, der die Arbeitsleistung beeinflusst.
- Abhängige Variablen (endogene Variablen):
- Dies sind Variablen, die von anderen Variablen im Modell beeinflusst werden. Man kann sie als Ergebnisse oder Effekte betrachten.
- In der SEM können abhängige Variablen auch als Mediatoren fungieren und andere abhängige Variablen beeinflussen.
- Beispiel: In derselben Studie ist die Arbeitsleistung die abhängige Variable, auf die sich der Bildungsgrad auswirkt.
- Störvariablen:
- Dies sind Variablen, die sowohl mit den unabhängigen als auch mit den abhängigen Variablen in Zusammenhang stehen und, wenn sie nicht angemessen kontrolliert werden, einen Scheinzusammenhang zwischen ihnen erzeugen können.
- Bei der SEM müssen Störvariablen berücksichtigt werden, um verzerrte Schätzungen der Zusammenhänge zwischen den untersuchten Variablen zu vermeiden.
- Beispiel: In der Studie zu Bildung und Arbeitsleistung könnten sowohl die psychische als auch die körperliche Gesundheit als Störvariablen wirken, da sie sowohl das Bildungsniveau als auch die Arbeitsleistung beeinflussen könnten.

- Latente Variablen:
- Dies sind Variablen, die nicht direkt beobachtet werden, sondern aus anderen beobachteten Variablen (Indikatorvariablen) abgeleitet werden.
- Latente Variablen stehen für zugrunde liegende Konstrukte, von denen angenommen wird, dass sie die beobachteten Variablen bedingen. Sie sind ein zentrales Konzept in der strukturellen Modellierung (SEM) und werden in Pfaddiagrammen üblicherweise als Kreise oder Ovale dargestellt (siehe nächstes Kapitel).
- Beispiele für latente Variablen sind Intelligenz, allgemeine Zufriedenheit oder sozioökonomischer Status, Familienstruktur usw.
- Beobachtete Variablen (manifeste Variablen):
- Beobachtete Variablen, auch als manifeste Variablen oder Indikatoren bezeichnet, werden direkt gemessen und liefern die Daten, anhand derer auf latente Variablen geschlossen wird. Dabei handelt es sich um die tatsächlichen Antworten oder Werte, die aus Umfragen, Tests oder anderen Messinstrumenten (Biosensoren) gewonnen werden.
- In der SEM werden beobachtbare Variablen zur Messung latenter Variablen verwendet (sie fungieren als Indikatoren) und können zudem als unabhängige oder abhängige Variablen dienen.
Visualisierung von Strukturgleichungsmodellen mit Pfaddiagrammen
In diesem Beispiel haben wir ein sehr einfaches Pfaddiagramm gewählt, um zu veranschaulichen, wie ein SEM dargestellt werden kann.
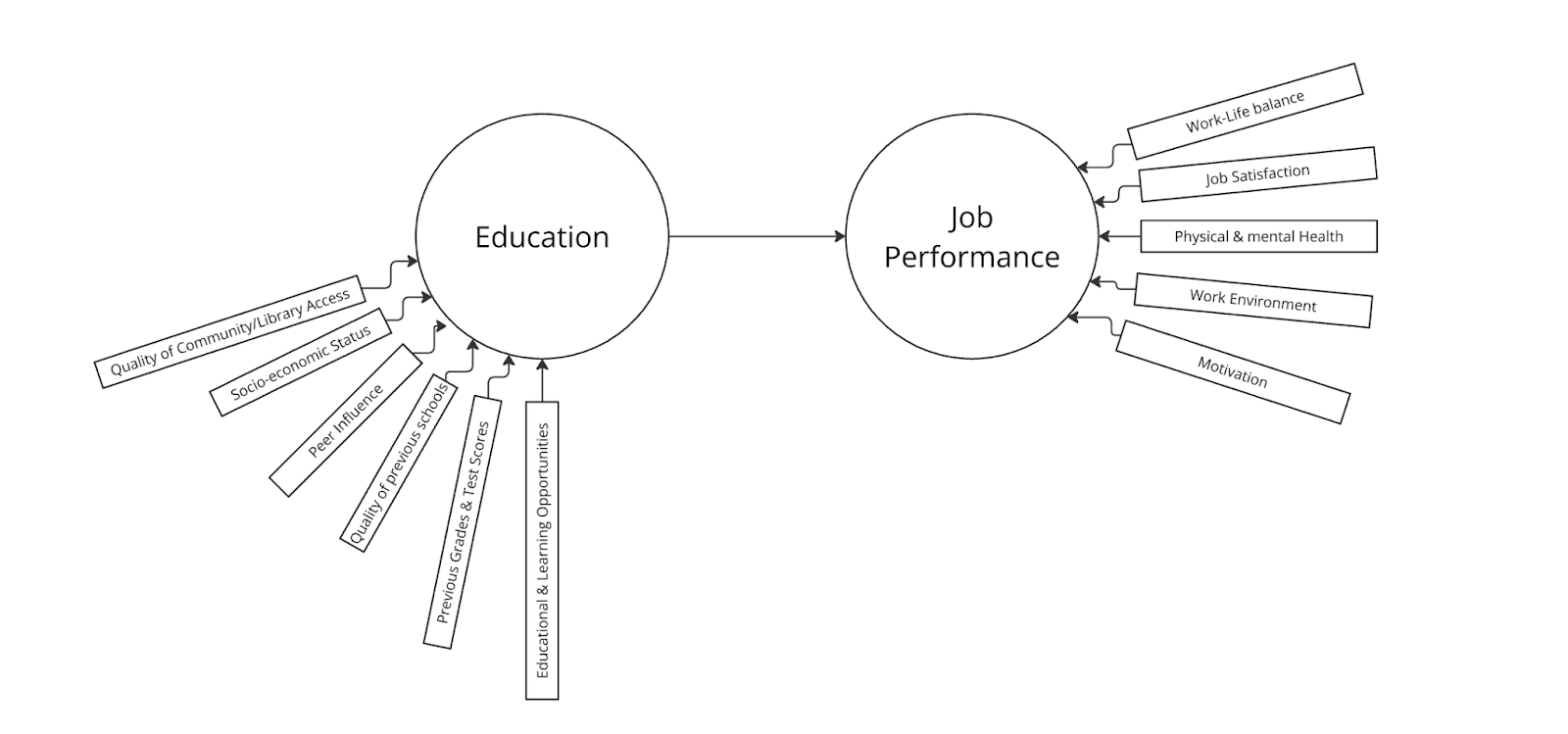
Um das obige Beispiel fortzusetzen, beschränken wir uns darauf, die Auswirkungen der Bildung (unabhängige Variable) auf die Arbeitsleistung (abhängige Variable) zu untersuchen. Nun könnten wir uns dafür entscheiden, ausschließlich den Einfluss der Bildung als Prädiktor auf die Arbeitsleistung als Ergebnisvariable zu untersuchen.
Um jedoch ein wesentlich umfassenderes Bild zu erhalten, können wir auch eine Reihe von spezifizierenden Variablen einbeziehen. Diese Variablen können hinzugefügt werden, um zu verdeutlichen, dass Bildung und Arbeitsleistung nicht nur absolute Werte an sich sind, sondern dass eine Vielzahl von Einflussfaktoren eine Rolle spielt, die die „Bildung“ oder „Arbeitsleistung“ einer Person ausmachen.
Die Bildung oder der Bildungsstand einer Person kann durch Faktoren wie den Zugang zu einer öffentlichen Bibliothek (und die Bereitschaft, diese zu nutzen), außerschulische Lernmöglichkeiten, demografische Faktoren wie die Qualität der Schulen in der Umgebung sowie den sozioökonomischen Status der Eltern beeinflusst werden. Auch die bisherigen schulischen Leistungen, die in der Regel anhand von Testergebnissen gemessen werden, können eine Rolle spielen, und schwerer quantifizierbare Variablen wie der Einfluss von Gleichaltrigen können ebenfalls den Bildungsstand einer Person beeinflussen.
Dabei könnte es sich um einzelne Regressionsanalysen handeln, die das allgemeine Bildungsniveau vorhersagen. Darüber hinaus sollten wir auch berücksichtigen, dass die Arbeitsleistung nicht nur von der bisherigen Bildung beeinflusst wird, sondern auch von den Bedingungen und Motivationen, die zur Bewertung der Tätigkeit selbst beitragen, und diese quantifizieren, um zu verstehen, wie viel der Varianz, die zur Arbeitsleistung beiträgt, allein auf die Bildung zurückzuführen ist.
Wenn all diese Variablen in das einfache Modell „Bildung -> Arbeitsleistung“ einbezogen werden, könnte es in etwa so aussehen.
Warum sollte man die Strukturgleichungsmodellierung einsetzen?
Herkömmliche statistische Modelle konzentrieren sich in der Regel auf die Analyse des direkten Effekts einer unabhängigen Variablen auf eine abhängige Variable. Diese Modelle versagen jedoch häufig dabei, die zahlreichen moderierenden und vermittelnden Faktoren zu berücksichtigen, die diese Beziehung beeinflussen können. Um den Effekt der unabhängigen Variable zu isolieren, müssen Forscher im Studiendesign so viele Störvariablen wie möglich kontrollieren, was die ökologische Validität der Studie potenziell verringern kann. Dennoch ist es manchmal entscheidend, alle Variablen in ein umfassendes und vernetztes Modell einzubeziehen, da sie auf komplexe Weise vermitteln und interagieren.
Der Weg zu einem Strukturgleichungsmodell
Beispiel: Die Wahl der Spendenempfänger bei Millennials
Um den Übergang zur Verwendung der Strukturgleichungsmodellierung (SEM) zu veranschaulichen, betrachten wir eine Studie, die die Entscheidungen von Millennials hinsichtlich wohltätiger Spenden untersucht. In einer kontrollierten Studie könnten Forscher ihren Fokus auf eine bestimmte demografische Gruppe eingrenzen, beispielsweise Personen im Alter von 35 bis 40 Jahren, die in Kopenhagen geboren und aufgewachsen sind und über ein Einkommen von mehr als 70.000 Euro verfügen. Sie würden untersuchen, ob und wie sich diese Personen wohltätig engagieren.
Dieser gezielte Ansatz könnte einen linearen Zusammenhang zwischen einem Anstieg des Einkommens und dem prozentualen Anteil der für wohltätige Zwecke ausgegebenen Gelder aufzeigen. Durch die Ausweitung der Studie auf eine breitere Altersspanne und unterschiedliche Einkommensniveaus können die Forscher jedoch Wechselwirkungen zwischen Generationsunterschieden und dem Einkommen in Bezug auf wohltätiges Handeln untersuchen.

Wenn Forscher andere implizite Faktoren wie gesellschaftliche Ansichten berücksichtigen, müssen sie diese Variablen zunächst herausrechnen oder immer komplexere Regressionsmodelle erstellen. Um beispielsweise die Spendenentscheidungen einer vielfältigen, kosmopolitischen Gesellschaft wie der in Kopenhagen zu untersuchen, benötigen Forscher umfassende demografische Daten. Dazu gehören Alter, Religionszugehörigkeit, politische Überzeugungen, Nutzung sozialer Medien, persönliches und familiäres Einkommen, Beziehungsstatus, Alter der Kinder (falls vorhanden) sowie der berufliche Tätigkeitsbereich.
Einsatz von Biosensoren zur Verbesserung der Variablen in Strukturgleichungsmodellen
Die Einbindung von Biosensoren in die Strukturgleichungsmodellierung (SEM) erweitert deren Leistungsfähigkeit erheblich, indem sie die Dimension der beobachteten Variablen hinzufügt. Biosensoren liefern objektive Echtzeitdaten zu physiologischen Reaktionen wie Herzfrequenzvariabilität, Hautleitfähigkeit und Gehirnaktivität. Diese Messungen sind entscheidend für das Verständnis der zugrunde liegenden biologischen Prozesse, die mit psychologischen und wirtschaftlichen Verhaltensweisen in Entscheidungsprozessen einhergehen. Durch die Einbeziehung von Biosensordaten in die SEM können Forscher genauere und differenziertere Modelle erstellen. So können sie beispielsweise untersuchen, wie physiologische Stressreaktionen die Beziehung zwischen wirtschaftlicher Not und psychischer Belastung vermitteln.
Schritte zur Implementierung von Biosensoren im REM
Abstimmung von Biosensordaten mit theoretischen Modellen
Zunächst müssen Forscher sicherstellen, dass die Biosensordaten mit den theoretischen Konstrukten ihres Modells übereinstimmen. Dazu gehört die Validierung physiologischer Messgrößen als Indikatoren für die interessierenden latenten Variablen. So könnte beispielsweise die Herzfrequenzvariabilität als Indikator für Stress validiert werden, während die Hautleitfähigkeit als Indikator für emotionale Erregung validiert werden könnte.
Integration von Biosensordaten mit herkömmlichen Daten
Anschließend müssen die über Biosensoren erfassten Daten mit herkömmlichen Erhebungs- oder Beobachtungsdaten zusammengeführt werden. Dies erfordert ausgefeilte Datenverarbeitungsverfahren zur Synchronisierung und Analyse multimodaler Datenströme – ein Prozess, der durch den Einsatz von iMotions vereinfacht wird, da diese Lösung eine nahtlose Synchronisierung von Datenströmen aus zahlreichen Datenquellen in Echtzeit ermöglicht.
Beispielsweise könnten Forscher Umfragedaten zum empfundenen Stresslevel erheben und gleichzeitig die Herzfrequenzvariabilität mithilfe eines Biosensors messen. Die Herausforderung besteht darin, sicherzustellen, dass Zeitpunkt und Kontext dieser Messungen aufeinander abgestimmt sind.

Die Verwendung der Strukturgleichungsmodellierung zur Überprüfung komplexer Hypothesen
Sobald die Datenintegration abgeschlossen ist, kann SEM genutzt werden, um komplexe Hypothesen über die Zusammenhänge zwischen psychologischen, wirtschaftlichen und physiologischen Variablen zu überprüfen. So könnte ein Forscher beispielsweise mithilfe von SEM untersuchen, ob finanzielle Unsicherheit zu erhöhtem Stress führt, was wiederum Veränderungen der physiologischen Reaktionen hervorruft, die zu psychischen Problemen beitragen. Ein weiteres Beispiel wäre der Einsatz einer impliziten Assoziationsaufgabe zum Verständnis sozialer und politischer Präferenzen, wobei die durch Biosensoren gemessenen physiologischen Reaktionen tiefere Einblicke liefern.
Vorteile der Verwendung von Biosensordaten in der Rasterelektronenmikroskopie
Durch die Kombination von SEM mit Biosensordaten können sich Forscher auf implizite Messwerte und physiologische Reaktionen stützen, anstatt sich ausschließlich auf selbstberichtete Umfrageergebnisse zu verlassen. Dieser Ansatz bietet mehrere Vorteile:
- Objektive Messung: Biosensoren liefern objektive Echtzeitdaten, die nicht durch subjektive Verzerrungen oder Ungenauigkeiten bei der Selbstauskunft beeinflusst werden.
- Umfassende Daten: Physiologische Daten, wie beispielsweise mittels EKG gemessener Stress oder mittels Eye-Tracking erfasste Präferenzen, bereichern das SEM-Modell, indem sie zusätzliche Informationsebenen hinzufügen, die mit herkömmlichen Methoden nur schwer zu erfassen sind.
- Erhöhte Genauigkeit: Durch die Einbeziehung von Biosensordaten lassen sich robustere und präzisere Modelle entwickeln, was zu einem besseren Verständnis der komplexen Wechselwirkungen zwischen den Variablen führt.
Anwendungsbeispiel
Da dieses Thema recht komplex sein kann, sehen wir uns ein weiteres Beispiel an. Stellen wir uns eine Studie vor, die die Auswirkungen finanzieller Unsicherheit auf die psychische Gesundheit untersucht. Bei traditionellen Methoden würden möglicherweise selbstberichtete Daten zu finanziellem Stress und psychischen Gesundheitsergebnissen verwendet. Durch die Einbeziehung von Biosensordaten können Forscher beobachtete Variablen wie Herzfrequenzvariabilität und Hautleitfähigkeit hinzufügen, um physiologische Stressreaktionen zu messen. Mit Hilfe der SEM lässt sich dann prüfen, ob finanzielle Unsicherheit zu erhöhtem physiologischem Stress führt, der sich wiederum auf die psychische Gesundheit auswirkt. Dieser ganzheitliche Ansatz bietet ein umfassenderes Verständnis der Wege, über die finanzielle Unsicherheit das psychische Wohlbefinden beeinflusst.